A Bit Sensational
I don’t really mean that unrelated queries block each other, but it sure does look like they do.
Implicit Transactions are really horrible surprises, but are unfortunately common to see in applications that use JDBC drivers to connect to SQL Server, and especially with applications that are capable of using other database platforms like Oracle as a back-end.
The good news is that in the latter case, support for using Read Committed Snapshot Isolation (RCSI) is there to alleviate a lot of your problems.
Problem, Child
Let’s start with what the problem looks like.

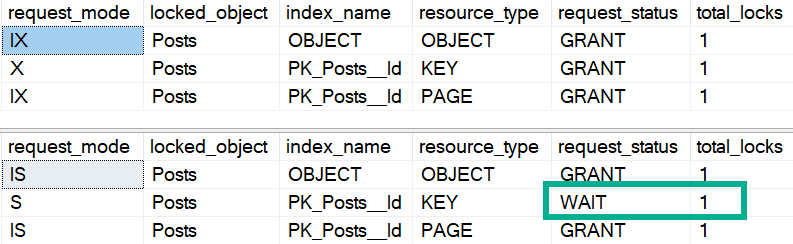
A couple unrelated select queries are blocking each other. One grabbing rows from the Users table, one grabbing rows from the Posts table.
This shouldn’t be!
Even if you run sp_WhoIsActive in a way to try to capture more of the command text than is normally shown, the problem won’t be obvious.
sp_WhoIsActive
@get_locks = 1;
GO
sp_WhoIsActive
@get_locks = 1,
@get_full_inner_text = 1,
@get_outer_command = 1;
GO
What Are Locks?
If we look at the details of the locks column from the output above, we’ll see the select query has locks on Posts:
<Database name="StackOverflow2013">
<Locks>
<Lock request_mode="S" request_status="GRANT" request_count="1" />
</Locks>
<Objects>
<Object name="Posts" schema_name="dbo">
<Locks>
<Lock resource_type="KEY" index_name="PK_Posts_Id" request_mode="X" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="IX" request_status="GRANT" request_count="1" />
<Lock resource_type="PAGE" page_type="*" index_name="PK_Posts_Id" request_mode="IX" request_status="GRANT" request_count="1" />
</Locks>
</Object>
</Objects>
</Database>
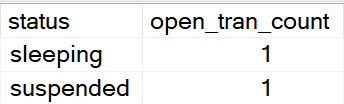
We may also note something else quite curious about the output. The select from Users is sleeping, with an open transaction.
How It Happens
The easiest way to show you is with plain SQL commands, but often this is a side effect of your application connection string.
In one window, step through this:
--Run this and stop
SET IMPLICIT_TRANSACTIONS ON;
--Run this and stop
UPDATE p
SET p.ClosedDate = SYSDATETIME()
FROM dbo.Posts AS p
WHERE p.Id = 11227809;
--Run this and stop
SELECT TOP (10000)
u.*
FROM dbo.Users AS u
WHERE u.Reputation = 2
ORDER BY u.Reputation DESC;
--Don't run these last two until you look at sp_WhoIsActive
IF @@TRANCOUNT > 0 ROLLBACK;
SET IMPLICIT_TRANSACTIONS OFF;
In another window, run this:
--Run this and stop
SET IMPLICIT_TRANSACTIONS ON;
--Run this and stop
SELECT TOP (100)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = 0
ORDER BY p.Score DESC;
--Don't run these last two until you look at sp_WhoIsActive
IF @@TRANCOUNT > 0 ROLLBACK;
SET IMPLICIT_TRANSACTIONS OFF;
How To Fix It
Optimistically:
If you’re using implicit transactions, and queries execute together, you won’t always see the full batch text. At best, the application will be written so that queries using implicit transactions will close out immediately. At worst, there will be some bug, or some weird connection pooling going on so that sessions never actually commit and release their locks.
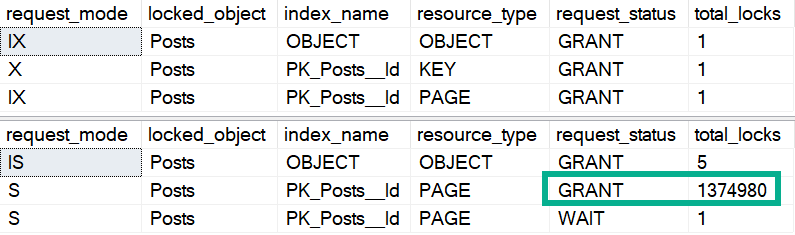
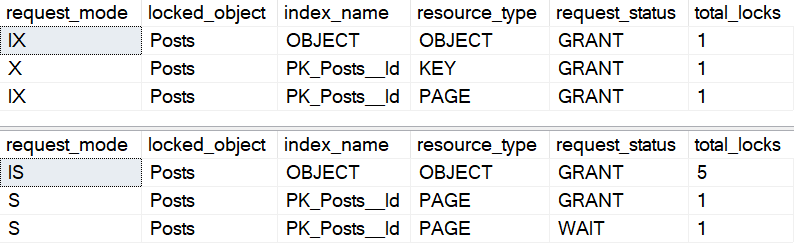
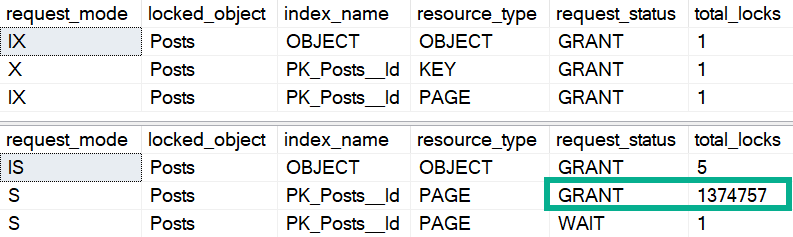
Fortunately, using an optimistic isolation level alleviates the issue, since readers and writers don’t block each other. RCSI is the easiest for this situation usually, because Snapshot Isolation (SI) requires queries to request it specifically.
Of course, if you’re issuing other locking hints at the query level already that enforce more strict isolation levels, like READCOMMITEDLOCK, HOLDLOCK/SERIALIZABLE, or REPEATABLE READ, RCSI won’t help. It will be overruled, unfortunately.
Programmatically:
You could very well be using this in your connection string by accident. If you have control over this sort of thing, change the gosh darn code to stop using it. You probably don’t need to be doing this, anyway. If for some reason you do require it, you probably need to dig a bit deeper in a few ways:
- Is there a bug in your code that’s causing queries not to commit?
- Is there something amok with connection pooling?
Going a little deeper, there could also be some issues with indexes, or the queries that are modifying data that are contributing to excess locking. Again, RCSI is a quick fix, and changing the connection string is a good idea if you can do it, but don’t ignore these long-term.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.