Fledgling
Like many things, applications tend to evolve over time. New and improved functionality, Bug Fixed And Performance Improvements™, and ever expanding schema usually lead to new queries or tweaks to existing ones.
When designing new queries, creating or tweaking indexes to help them along is perhaps a bit more intuitive, depending on how comfortable you are with such things. If you’re starting from near-zero there, check the link at the end of my post for 75% off of my video training. I’ll teach you how to design effective indexes.
One of the more common issues I see is that someone tweaked a query to support new functionality, and it just happened to use indexes well-enough in a development environment that’s much smaller than real customer deployments.
In these cases, a better index may not be recommended by SQL Server. If it’s not obvious to the optimizer, it may also not be obvious to you, either. No offense.
All Devils
Let’s say we have this query. It’s nothing magnificent, but it’s enough to prove a couple points.
CREATE INDEX c ON dbo.Comments(CreationDate, UserId);
SELECT TOP (1000)
C.CreationDate,
C.Score,
C.Text,
DisplayName =
(
SELECT
U.DisplayName
FROM dbo.Users AS U
WHERE U.Id = C.UserId
)
FROM dbo.Comments AS C
WHERE C.CreationDate >= '20131215'
ORDER BY C.CreationDate DESC;
Our index serves three purposes:
- The predicate on CreationDate
- The order by on CreationDate
- The correlated subquery on UserId
It’s important to keep things like this in mind, that sorted data is useful for making more efficient.
Let’s Go
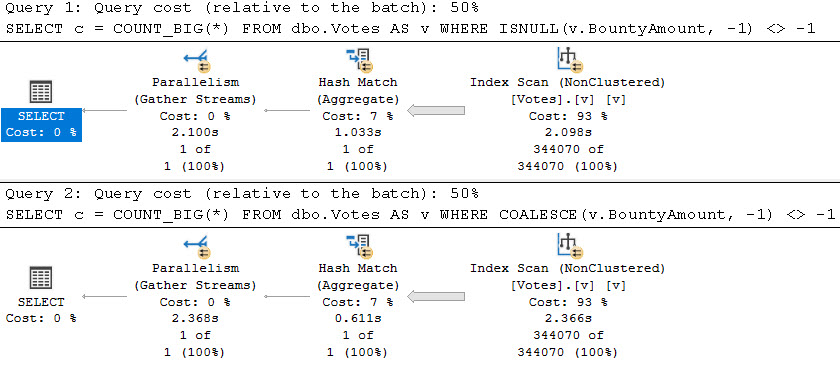
The query plan for this is quite simple and efficient.
It’s hard to ask for anything faster, here, even if I am running on a VM. Two seeks, a small lookup, and everything done in 5 milliseconds.
Wolves At
But then one day a pull request comes along that changes the query slightly, to let us also filter and order by the Score column.
It looks like this now:
SELECT TOP (1000)
C.CreationDate,
C.Score,
C.Text,
DisplayName =
(
SELECT
U.DisplayName
FROM dbo.Users AS U
WHERE u.Id = C.UserId
)
FROM dbo.Comments AS C
WHERE C.CreationDate >= '20131215'
AND C.Score >= 8
ORDER BY
C.CreationDate DESC,
C.Score DESC;
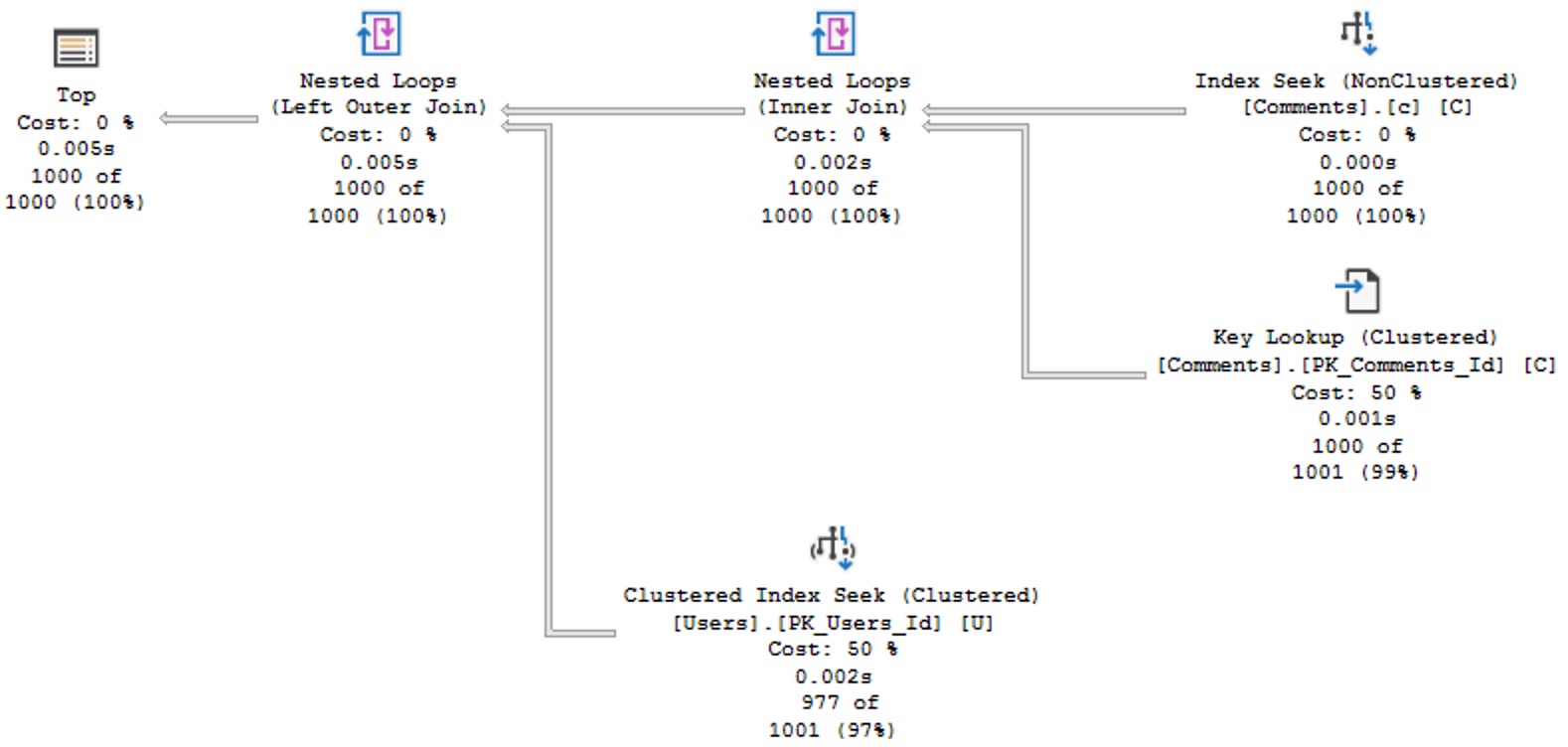
In real life, if you’re smart, your queries will be parameterized. In this blog post, these values are to show you what can happen even with small changes to a query. The query plan looks like this now:
Arf Arf
We still seek into our nonclustered index to search for CreationDates that pass our predicate, but now we need to evaluate the Score predicate when we do our key lookup.
Rather than just get 1000 rows out immediately, we need to keep findings rows that pass the CreationDate predicate, but that also pass the Score predicate.
Since that’s judged by the optimizer to be a much more “expensive” task, and a parallel plan is chosen. Despite that, it still takes 231 milliseconds of duration, with 844 milliseconds of CPU time.
This could have many effects on the workload, depending on how frequently a query executes within the workload. Parallel queries use more CPU threads, which can get tricky under high concurrency, since they’re a finite resource based on CPU count.
We can save a lot of the problems here with a slightly adjusted index, like this:
CREATE INDEX c ON dbo.Comments(CreationDate, Score, UserId);
Delicious
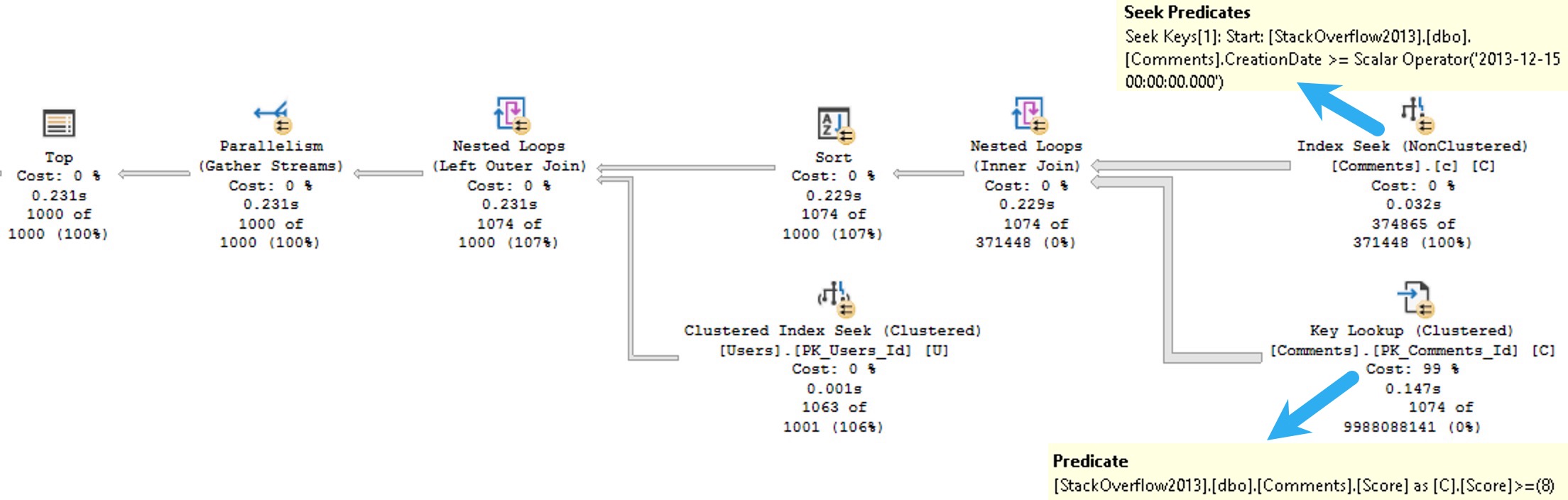
With that index in place, we get a much more efficient plan back, that doesn’t need to go parallel to stay competitively fast. It’s not quite as fast as the original query, but it’s Good Enough™.
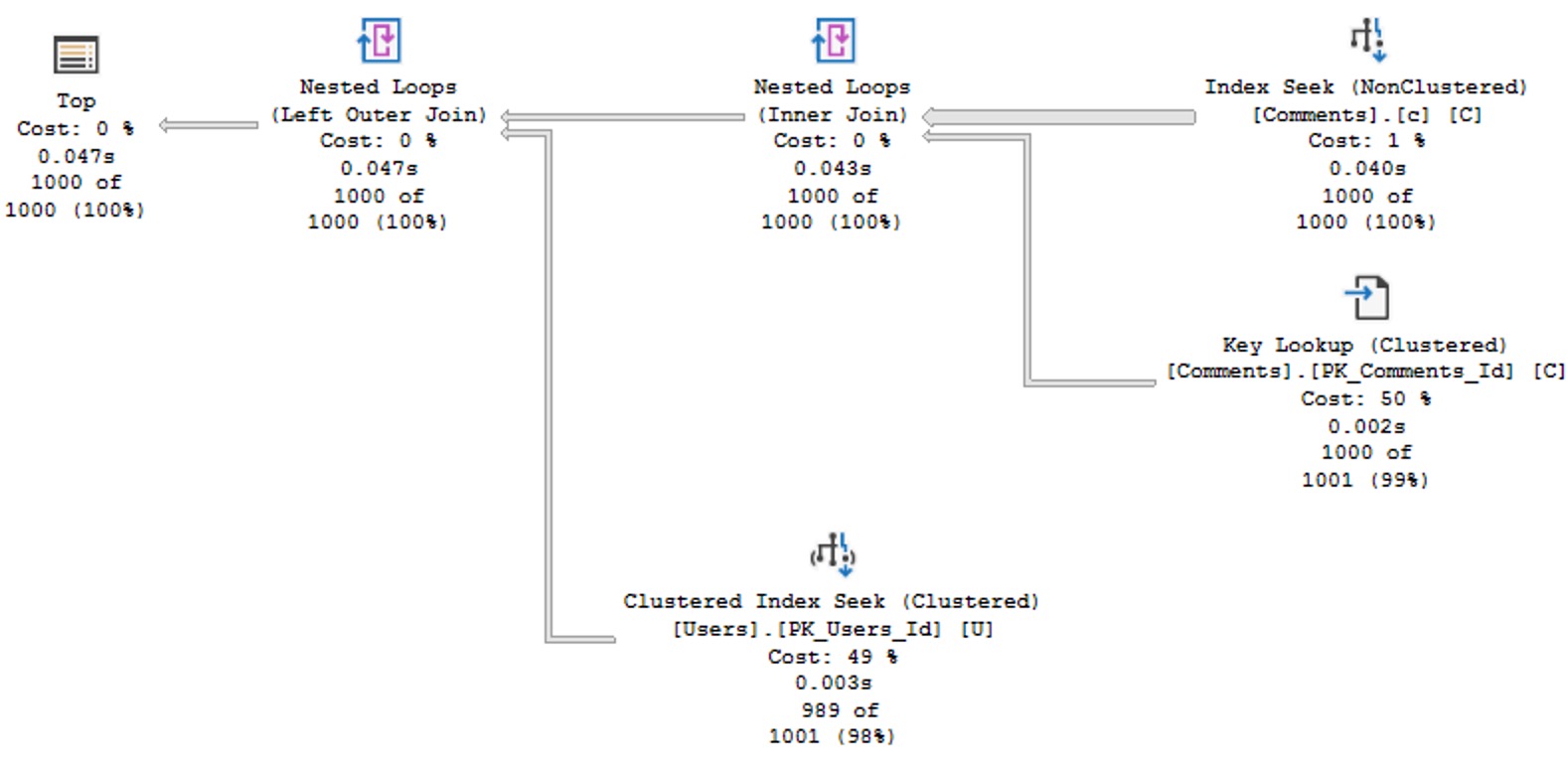
Cheese Wants
I know you’re all smart folks out there, and you’re going to have questions about the index I created, and why the columns are in the order they’re in.
If you have a copy of the StackOverflow2013 database, you might do some poking around and find that there are 374,865 rows that pass our CreationDate predicate, and only 122,402 that pass our Score filter, making Score more selective for this version of the query.
But that’s just this one execution, and things could be a lot different depending on what users filter on. The big advantage to keeping the columns in this order is that the order by remains supported. Without that, the optimizer goes back to choosing a parallel plan, and asking for a memory grant.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.