While the Parameter Sensitive Plan (PSP) optimization won’t fix every problem with this lazy coding habit, it can fix some of them in very specific circumstances, assuming:
The parameter is eligible for PSP
The parameter is present across IF branches
We’re going to use a simple one parameter example to illustrate the potential utility here.
After all, if I make these things too complicated, someone might leave a comment question.
The horror
IFTTT
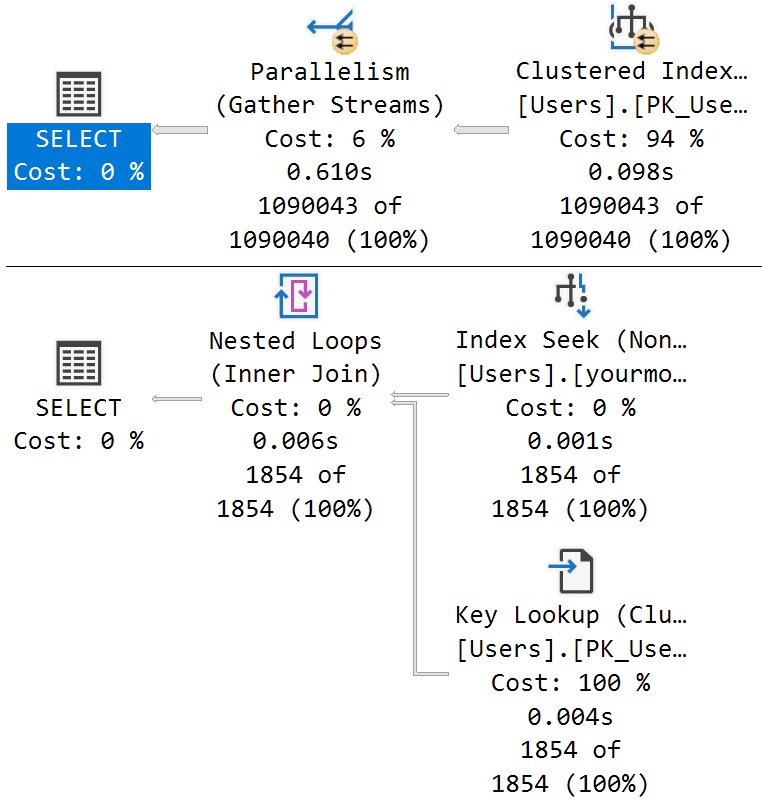
Here’s the procedure we’re using. The point is to execute one branch if @Reputation parameter is equal to one, and another branch if it equals something else.
In the bad old days, both queries would get a plan optimized at compile time, and neither one would get the performance boost that you hoped for.
In the good news days that you’ll probably get to experience around 2025, things are different!
CREATE OR ALTER PROCEDURE
dbo.IFTTT
(
@Reputation int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SET STATISTICS XML ON;
IF @Reputation = 1
BEGIN
SELECT
u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation;
END;
IF @Reputation > 1
BEGIN
SELECT
u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation = @Reputation;
END;
SET STATISTICS XML OFF;
END;
GO
Johnson & Johnson
If we execute these queries back to back, each one gets a new plan:
EXEC dbo.IFTTT
@Reputation = 1;
GO
EXEC dbo.IFTTT
@Reputation = 2;
GO
psychic driving
Optimize For You
The reason why is in the resulting queries, as usual. The Reputation column has enough skew present to trigger the PSP optimization, so executions with differently-bucketed parameter values end up with different plans.
And of course, each plan has different compile and runtime values:
care
If I were to run this demo in a compatibility level under 160, this would all look totally different.
This is one change I’m sort of interested to see the play-out on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
After seeing places where the Parameter Sensitive Plan (PSP) optimization quite stubbornly refuses to kick in, it’s somewhat amusing to see it kick in where it can’t possibly have any positive impact.
Even though some parameters are responsible for filtering on columns with highly skewed data, certain other factors may be present that don’t allow for the type of plan quality issues you might run into under normal parameter sensitivity scenarios:
Adequate indexing
Row goals
Other filtering elements
This isn’t to say that they can always prevent problems, but they certainly tend to reduce risks much of the time.
If only everything were always ever perfect, you know?
Setup
Let’s start by examining some data in the Posts table.
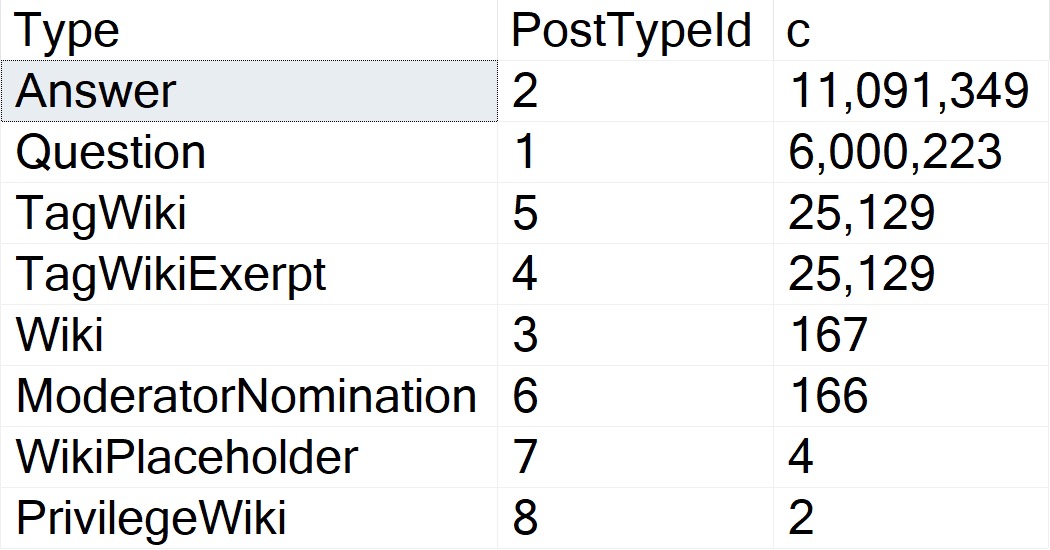
First, PostTypeIds:
resultant
Questions and answers are the main types of Posts. The data is clearly skewed, here, and in my testing this does qualify for PSP on its own.
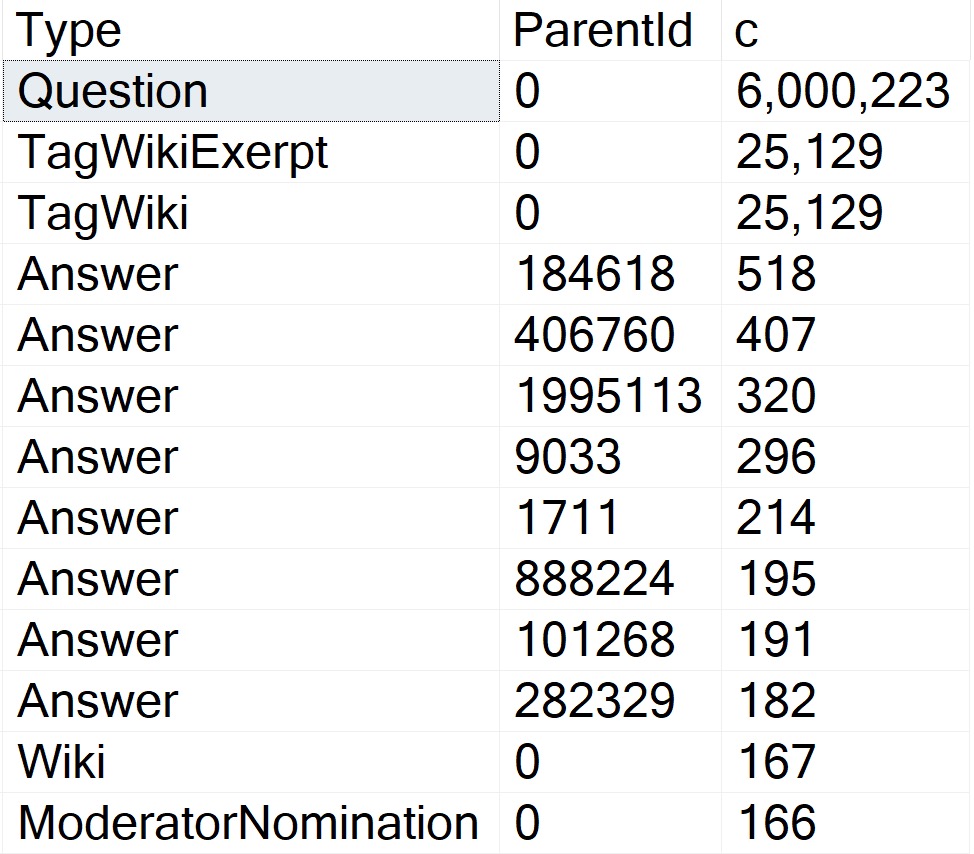
The thing is, there are several attributes that Questions can have that Answers can’t. One of those is a ParentId. Looking through how the top 15 or so of those counts breaks down:
hitherto
Okay, so! Wikis don’t have ParentIds, neither do Moderator Nominations. More importantly, Questions don’t.
The Question with the Most answers is Id 184618, with 518. A far cry from the next-nearest Post Types, and light years from the number of Questions with a ParentId of zero.
More important than loving your data is knowing your data.
To Query A Butterfly
Let’s say we have this query:
SELECT TOP (5000)
p.Id,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = @po
AND p.ParentId = @pa
ORDER BY
p.Score DESC;
The three things we care about getting done are:
Filtering to PostTypeId
Filtering to ParentId
Ordering by Score
Either of these indexes would be suitable for that:
CREATE INDEX
popa
ON dbo.Posts
(
PostTypeId,
ParentId,
Score DESC
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
CREATE INDEX
papo
ON dbo.Posts
(
ParentId,
PostTypeId,
Score DESC
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
With No PSP At All
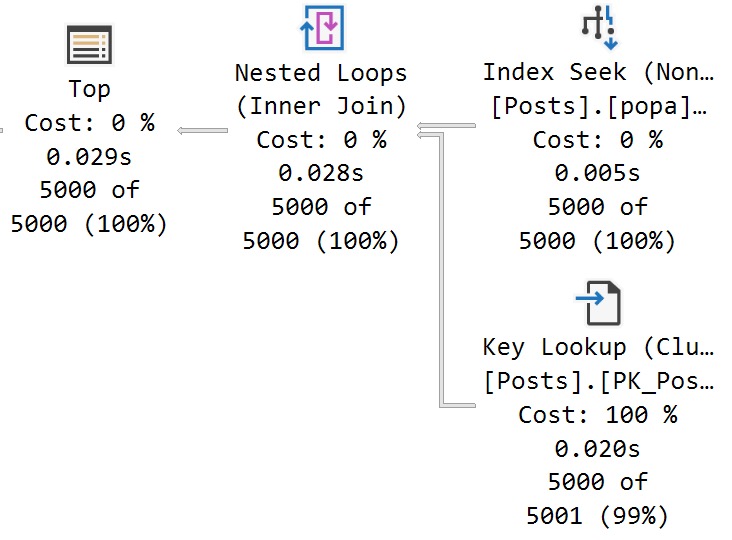
Under compatibility level 150, we can run the query in a variety of ways and get nearly identical performance results:
There’s a 27 millisecond difference between the two to find the first 5000 rows that match both predicates. You would have to run these in a very long loop to accumulate a meaningful overall difference.
In this case, both queries use and reuse the same execution plan. You can see that in the estimates.
With All The PSP
Switching to compat level 160, the queries are injected with the PLAN PER VALUE hint.
SELECT TOP (5000)
p.Id,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = @po
AND p.ParentId = @pa
ORDER BY
p.Score DESC
OPTION
(
PLAN PER VALUE
(
QueryVariantID = 2,
predicate_range
(
[StackOverflow2013].[dbo].[Posts].[PostTypeId] = @po,
100.0,
10000000.0
)
)
)
SELECT TOP (5000)
p.Id,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.PostTypeId = @po
AND p.ParentId = @pa
ORDER BY
p.Score DESC
OPTION
(
PLAN PER VALUE
(
QueryVariantID = 3,
predicate_range
(
[StackOverflow2013].[dbo].[Posts].[PostTypeId] = @po,
100.0,
10000000.0
)
)
)
The thing is, both queries end up with identical execution times to when there was no PSP involved at all.
In other words, there is no parameter sensitivity in this scenario, despite there being skew in the column data.
Even searching for the “big” result — Questions with a ParentId of zero, finishes in <30 milliseconds.
Ah well. Gotta train the models somehow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s take a brief moment to talk about terminology here, so you don’t go getting yourself all tied up in knots:
Parameter Sniffing: When the optimizer creates and caches a plan based on a set of parameter(s) for reuse
Parameter Sensitivity: When a cached plan for one set of parameter(s) is not a good plan for other sets of parameter(s)
The first one is a usually-good thing, because your SQL Server won’t spend a lot of time compiling plans constantly. This is obviously more important for OLTP workloads than for data warehouses.
This can pose problems in either type of environment when data is skewed towards one or more values, because queries that need to process a lot of rows typically need a different execution plan strategy than queries processing a small number of rows.
This seems a good fit for the Intelligent Query Processing family of SQL Server features, because fixing it sometimes requires a certain level of dynamism.
Choice 2 Choice
The reason this sort of thing can happen often comes down to indexing. That’s obviously not the only thing. Even a perfect index won’t make nested loops more efficient than a hash join (and vice versa) under the right circumstances.
Probably the most classic parameter sensitivity issue, and why folks spend a long time trying to fix them, is the also-much-maligned Lookup.
But consider the many other things that might happen in a query plan that will hamper performance.
Join type
Join order
Memory grants
Parallelism
Aggregate type
Sort/Sort Placement
Batch Mode
The mind boggles at all the possibilities. This doesn’t even get into all the wacky and wild things that can mess SQL Server’s cost-based optimizer up a long the way.
With SQL Server 2022, we’ve finally got a starting point for resolving this issue.
In tomorrow’s post, we’ll talk a bit about how this new feature works to help with your parameter sensitivity issues, which are issues.
Not your parameter sniffing issues, which are not issues.
For the rest of the week, I’m going to dig deeper into some of the stuff that the documentation glosses over, where it helps, and show you a situation where it should kick in and help but doesn’t.
Keep in mind that these are early thoughts, and I expect things to evolve both as RTM season approaches, and as Cumulative Updates are released for SQL Server 2022.
Remember scalar UDF inlining? That thing morphed quite a bit.
Can’t wait for all of you to get on SQL Server 2019 and experience it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
WITH
queries AS
(
SELECT TOP (100)
parent_object_name =
ISNULL
(
OBJECT_NAME(qsq.object_id),
'No Parent Object'
),
qsqt.query_sql_text,
query_plan =
TRY_CAST(qsp.query_plan AS xml),
qsrs.first_execution_time,
qsrs.last_execution_time,
qsrs.count_executions,
qsrs.avg_duration,
qsrs.avg_cpu_time,
qsp.query_plan_hash,
qsq.query_hash
FROM sys.query_store_runtime_stats AS qsrs
JOIN sys.query_store_plan AS qsp
ON qsp.plan_id = qsrs.plan_id
JOIN sys.query_store_query AS qsq
ON qsq.query_id = qsp.query_id
JOIN sys.query_store_query_text AS qsqt
ON qsqt.query_text_id = qsq.query_text_id
WHERE qsrs.last_execution_time >= DATEADD(DAY, -7, SYSDATETIME())
AND qsrs.avg_cpu_time >= (10 * 1000)
AND qsq.is_internal_query = 0
AND qsp.is_online_index_plan = 0
ORDER BY qsrs.avg_cpu_time DESC
)
SELECT
qs.*
FROM queries AS qs
CROSS APPLY
(
SELECT TOP (1)
gqs.*
FROM sys.dm_db_missing_index_group_stats_query AS gqs
WHERE qs.query_hash = gqs.query_hash
AND qs.query_plan_hash = gqs.query_plan_hash
ORDER BY
gqs.last_user_seek DESC,
gqs.last_user_scan DESC
) AS gqs
ORDER BY qs.avg_cpu_time DESC
OPTION(RECOMPILE);
I don’t love this query, because I don’t love querying Query Store views. That’s why I wrote sp_QuickieStore to make it a whole lot easier.
But anyway, this will get you a similar bunch of information.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the quest for me trying to get people to upgrade to a not-old-and-busted version of SQL Server, this is one that I talk about a lot because it really helps folks who don’t have all the time in the world to tune queries and indexes.
Here’s a quick helper query to get you started:
SELECT TOP (50)
query_text =
SUBSTRING
(
st.text,
qs.statement_start_offset / 2 + 1,
CASE qs.statement_start_offset
WHEN -1
THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset / 2 + 1
),
qp.query_plan,
qs.creation_time,
qs.last_execution_time,
qs.execution_count,
qs.max_worker_time,
avg_worker_time =
(qs.total_worker_time / qs.execution_count),
qs.max_grant_kb,
qs.max_used_grant_kb,
qs.total_spills
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
CROSS APPLY
(
SELECT TOP (1)
gqs.*
FROM sys.dm_db_missing_index_group_stats_query AS gqs
WHERE qs.query_hash = gqs.query_hash
AND qs.query_plan_hash = gqs.query_plan_hash
AND qs.sql_handle = gqs.last_sql_handle
ORDER BY
gqs.last_user_seek DESC,
gqs.last_user_scan DESC
) AS gqs
ORDER BY qs.max_worker_time DESC
OPTION(RECOMPILE);
This should help you find queries that use a lot of CPU and might could oughtta use an index.
Note that this script does not assemble the missing index definition for you. That stuff is all readily available in the query plans that get returned here, and of course the missing index feature has many caveats and limitations to it.
You should, as often as possible, execute the query and collect the actual execution plan to see where the time is spent before adding anything in.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are a million scripts out there that will give you all of the missing index requests for a database (or even a whole server).
Some will even try to prioritize based on the metrics logged along with each request.
Right now, most of you get:
Uses: How many times a query compiled that could have used the index
Average Query Cost: A unit-less cost used by the optimizer for choosing a plan
Impact: A metric relative to the unit-less cost of the operator the index will help
Breaking each of those down, the only one that has a concrete meaning is Uses, but that of course doesn’t mean that a query took a long time or is even terribly inefficient.
That leaves us with Average Query Cost, which is the sum of each operator’s estimated cost in the query plan, and Impact.
But where does Impact come from?
Impactful
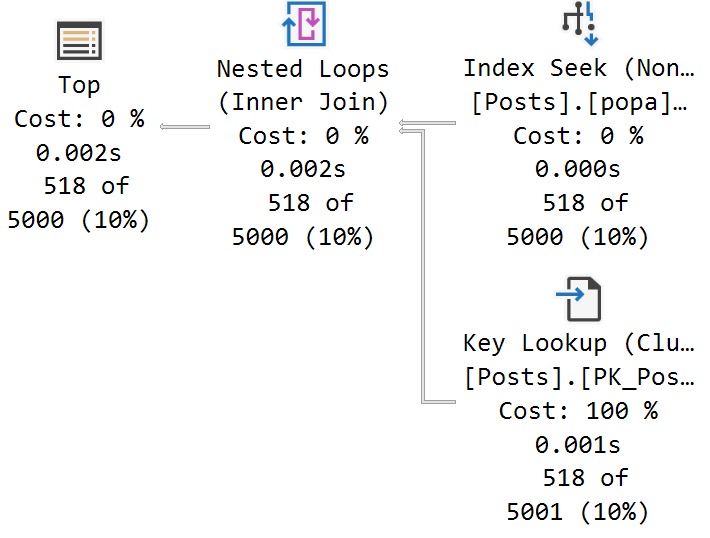
Let’s look at a query plan with a missing index request to figure out what the Impact metric is tied to.
Here’s the relevant part of the plan:
sticky kid
And here’s the missing index request:
/*
The Query Processor estimates that implementing the following index could improve the query cost by 16.9141%.
*/
/*
USE [StackOverflow2013]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [dbo].[Comments] ([Score])
INCLUDE ([PostId])
GO
*/
Here’s the breakdown:
The optimizer estimates that hitting the Comments table will cost 762 query bucks, which is 17% of the total plan cost
The optimizer further estimates that hitting the Comments table with the suggested index will reduce the total plan cost by 16.9%
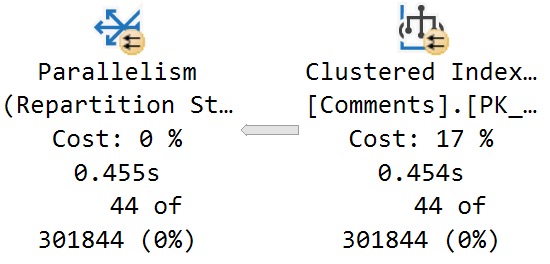
Here’s the relevant properties from the scan of the Comments table:
Indecisive
What I want you to take away from this is that, while hitting the Comments table may be 17% of the plan’s total estimated cost, the time spent scanning that index is not 17% of the plan’s total execution time, either in CPU or duration.
You can see in the screenshot above that it takes around 450ms to perform the full scan of 24,534,730 rows.
Doubtful
In full, this query runs for around 23 seconds:
outta here
The estimated cost of hitting the Comments tables is not 17% of the execution time. That time lives elsewhere, which we’ll get to.
In the meantime, there are two more egregious problems to deal with:
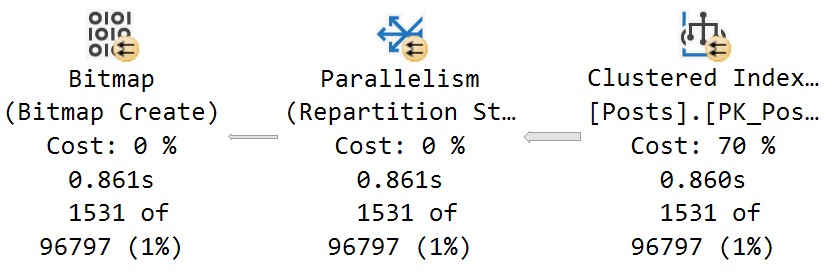
The optimizer severely miscalculates the cost of scanning the Posts table at 70% (note the 860ms time here):
oh no no no
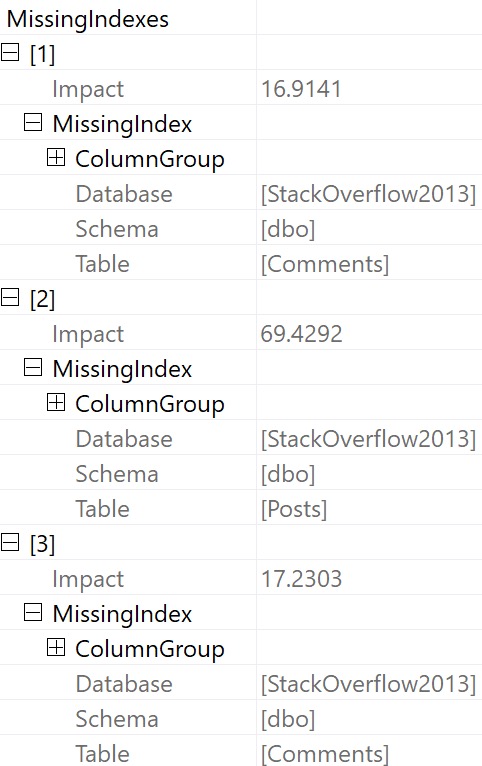
2. It buries other missing index requests in the properties of the root operator:
train tracks
Now, there are two other missing index requests listed here that are a) of higher “impact” b) not ordered by that impact number and c) even if both a and b were true, we know that adding those indexes would not substantially reduce the overall runtime of the stored procedure.
Assuming that we added every single missing index here, at best we would reduce the estimated cost of the plan by 87%, while only reducing the actual execution time of the plan by about 1.3 seconds out of 23 seconds.
Not a big win, here.
Hurtful
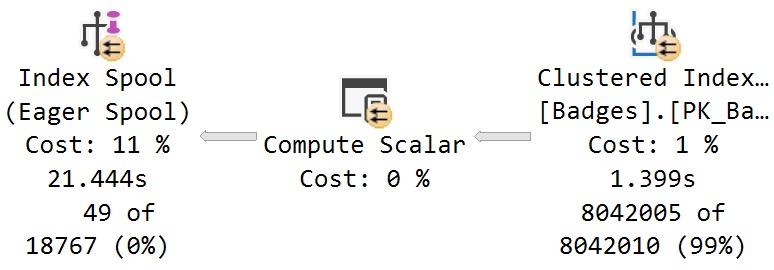
Examining where time is spent in this plan, this branch will stick out as the dominating factor:
baby don’t do it
Some interesting things to note here, while we’re talking about interesting things:
The scan of the Badges table takes 1.4 seconds, and has an estimated cost of 1%
The estimated cost of the eager index spool is 11%, but accounts for 20 seconds of elapsed time (less the 1.4 seconds for the scan of Badges)
There was no missing index request generated for the Badges table, despite the optimizer creating one on the fly
This is a bit of the danger in creating missing index requests without first validating which queries generated them, and where the benefit in having them would be.
In tomorrow’s post, we’ll look at how SQL Server 2019 makes figuring this stuff out easier.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You know those tables, right? The ones where developers went and got lazy or didn’t know any better and decided every string column was going to be gigantic.
They may have read, of course, that SQL Server’s super-smart variable length data types only consume necessary space.
It’s free real estate.
Except it isn’t, especially not when it comes to query memory grants.
The bigger a string column’s defined byte length is, the bigger the optimizer’s memory grant for it will be.
Memory Grant Primer
In case you need some background, the short story version is:
All queries ask for some memory for general execution needs
Sorts, Hashes, and Optimized Nested Loops ask for additional memory grants
Memory grants are decided based on things like number of rows, width of rows, and concurrently executing operators
Memory grants are divided by DOP, not multiplied by DOP
By default, any query can ask for up to 25% of max server memory for a memory grant
Approximately 75% of max server memory is available for memory grants at one
Needless to say, memory grants are very sensitive to misestimates by the optimizer. Going over can be especially painful, because that memory will most often get pulled from the buffer pool, and queries will end up going to disk more.
Underestimates often mean spills to disk, of course. Those are usually less painful, but can of course be a problem when they’re large enough. In particular, hash spills are worth paying extra attention to.
Memory grant feedback does supply some relief under modern query execution models. That’s a nice way of saying probably not what you have going on.
Query Noogies
Getting back to the point: It’s a real pain in the captain’s quarters to modify columns on big tables, even if it’s reducing the size.
SQL Server’s storage engine has to check page values to make sure you’re not gonna lose any data fidelity in the process. That’ a nice way of saying you’re not gonna truncate any strings.
But if you do something cute like run a MAX(LEN(StringCol) and see what you’re up against, you can use a view on top of your table to assuage SQL Server’s concerns about such things.
After all, functions are temporary. Data types are forever (usually).
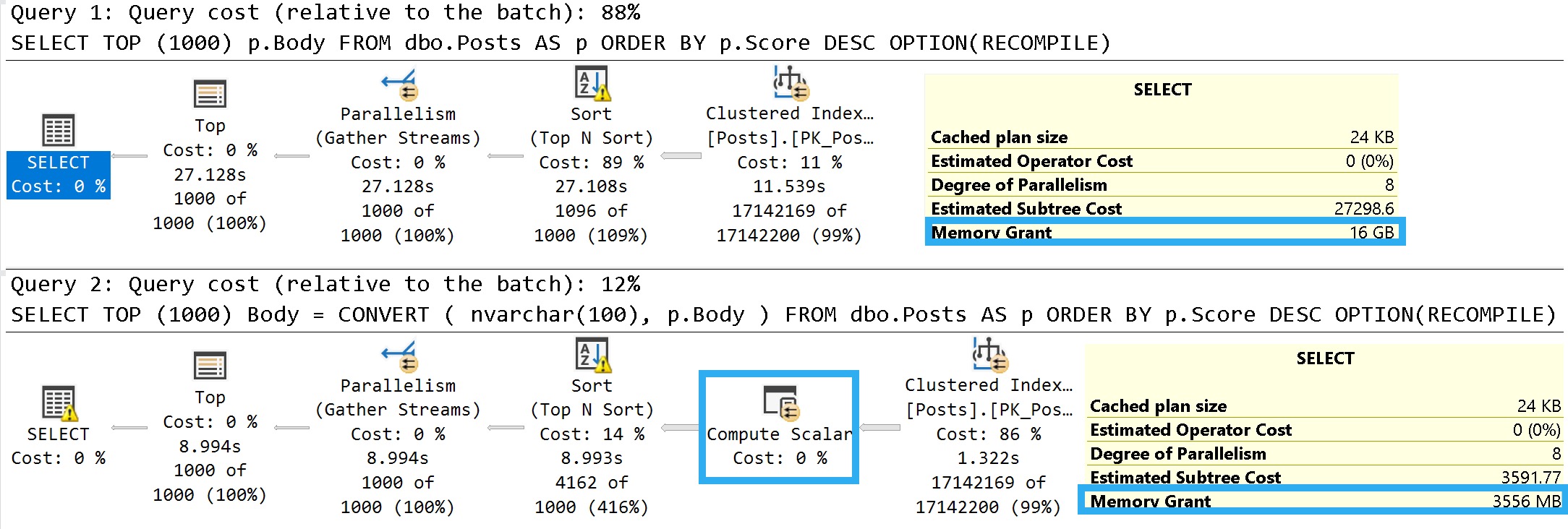
An easy way to illustrate what I mean is to look at the details of these two queries:
SELECT TOP (1000)
p.Body
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
SELECT TOP (1000)
Body =
CONVERT
(
nvarchar(100),
p.Body
)
FROM dbo.Posts AS p
ORDER BY p.Score DESC
OPTION(RECOMPILE);
Some of this working is dependent on the query plan, so let’s look at those.
Pink Belly Plans
You can ignore the execution times here. The Body column is not a good representation of an oversized column.
It’s defined as nvarchar(max), but (if I’m remembering my Stack lore correctly) is internally limited to 30k characters. Many questions and answers are longer than 100 characters anyway, but on to the plans!
janitor
In the plan where the Body column isn’t converted to a smaller string length, the optimizer asks for a 16GB memory grant, and in the second plan the grant is reduced to ~3.5GB.
This is dependent on the compute scalar occurring prior to the Top N Sort operator, of course. This is where the convert function is applied to the Body column, and why the grant is reduced
If you were to build a view on top of the Posts table with this conversion, you could point queries to the view instead. That would get you the memory grant reduction without the pain of altering the column, or moving the data into a new table with the correct definition.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In the age of column store indexes, indexed views have a bit less attractiveness about them. Unless of course you’re on Standard Edition, which is useless when it comes to column store.
I think the biggest mark in favor of indexed views over column store in Standard Edition is that there is no DOP restriction on them, where batch mode execution is limited to DOP 2.
One of the more lovely coincidences that has happened of late was me typing “SQL Server Stranded Edition” originally up above.
Indeed.
There are some good use cases for indexed views where column store isn’t a possibility, though. What I mean by that is they’re good at whipping up big aggregations pretty quickly.
Here are some things you oughtta know about them before trying to use them, though. The first point is gonna sound really familiar.
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, you’ll wanna use the NOEXPAND hint when you touch an indexed view. Not only because that’s the only way to guarantee the view definition doesn’t get expanded by the optimizer, but also because (even in Enterprise Edition) that’s the only way to get statistics generated on columns in the view.
If you’ve ever seen a warning for missing column statistics on an indexed view, this is likely why. Crazy town, huh?
Third, indexed views maintain changes behind the scenes automatically, and that maintenance can really slow down modifications if you don’t have indexes that support the indexed view definition.
Eighth, if your indexed view has an aggregation in it, you need to have a COUNT_BIG(*) column in the view definition.
Buuuuuut, if you don’t group by anything, you don’t need one.
Ninth, yeah, you can’t use DISTINCT in the indexed view, but if you can use GROUP BY, and the optimizer can match queries that use DISTINCT to your indexed view.
CREATE OR ALTER VIEW
dbo.shabu_shabu
WITH SCHEMABINDING
AS
SELECT
u.Id,
u.DisplayName,
u.Reputation,
Dracula =
COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation > 100000
GROUP BY
u.Id,
u.Reputation,
u.DisplayName;
GO
CREATE UNIQUE CLUSTERED INDEX
cuqadoodledoo
ON dbo.shabu_shabu
(
Id
);
SELECT DISTINCT
u.Id
FROM dbo.Users AS u
WHERE u.Reputation > 100000;
Ends up with this query plan:
balance
Tenth, the somewhat newly introduced GREATEST and LEAST functions do work in indexed views, which certainly makes things interesting.
I suppose that makes sense, since they’re probably just CASE expressions internally, but after everything we’ve talked about, sometimes it’s surprising when anything works.
Despite It All
When indexed views are the right choice, they can really speed up a lot of annoying aggregations among their other utilities.
This week we talked a lot about different things we can do to tables to make queries faster. This is stuff that I end up recommended pretty often, but there’s even more stuff that just didn’t make the top 5 cut.
Next week we’ll talk about some database and server level settings that can help fix problems that I end up telling clients to flip the switch on.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Remember yesterday? Yeah, me either. But I do have access to yesterday’s blog post, so I can at least remember that.
What a post that was.
We talked about filtered indexes, some of the need-to-know points, when to use them, and then a sad shortcoming.
Today we’re going to talk about how to overcome that shortcoming, but… there’s stuff you need to know about these things, too.
We’re gonna start off with some Deja Vu!
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, computed columns are sort of like regular columns: you can only search them efficiently if you index them.
This may come as a surprise to you, but indexes put data in order so that it’s easier to find things in them.
The second thing you should know about the second thing here is that you don’t need to persist computed columns to add an index to them, or to get statistics generated for the computed values (but there are some rules we’ll talk about later).
For example, let’s say you do this:
ALTER TABLE dbo.Users ADD TotalVotes AS (UpVotes + DownVotes);
CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The index gets created just fine. This is incredibly handy if you need to add a computed column to a large table, because there won’t be any blocking while adding the column. The index is another matter, depending on if you’re using Enterprise Edition.
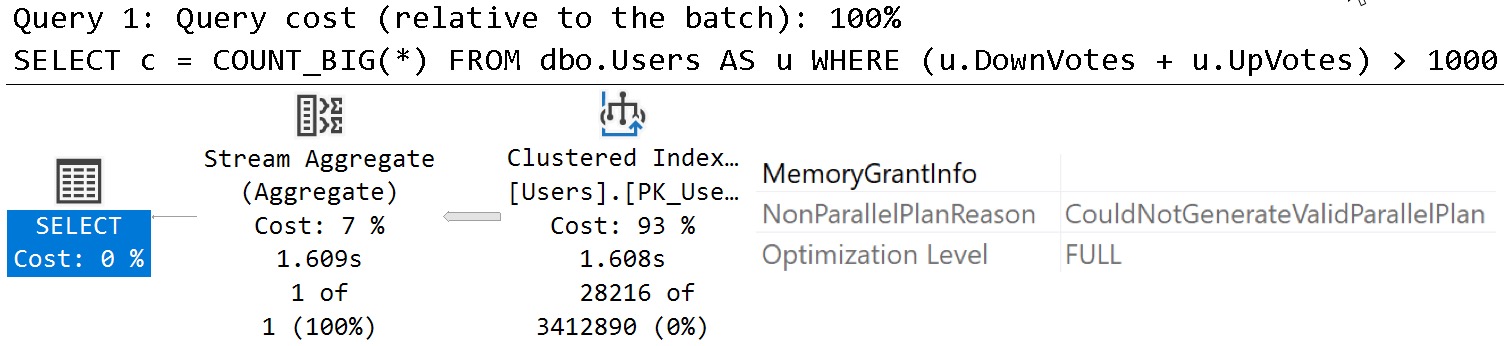
Third, SQL Server is picky about them, kind of. The problem is a part of the query optimization process called expression matching that… matches… expressions.
For example, these two queries both have expressions in them that normally wouldn’t be SARGable — meaning you couldn’t search a normal index on (Upvotes, Downvotes) efficiently.
But because we have an indexed computed column, one of them gets a magic power, and the other one doesn’t.
Because it’s backwards.
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.UpVotes + u.DownVotes) > 1000;
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;
connection
See what happens when you confuse SQL Server?
If you have full control of the code, it’s probably safer to reference the computed column directly rather than rely on expression matching, but expression matching can be really useful when you can’t change the code.
Fourth, don’t you ever ever never ever ever stick a scalar UDF in a computed column or check constraint. Let’s see what happens:
CREATE FUNCTION dbo.suck(@Upvotes int, @Downvotes int)
RETURNS int
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN (SELECT @Upvotes + @Downvotes);
END;
GO
ALTER TABLE dbo.Users ADD TotalVotes AS dbo.suck(UpVotes, DownVotes);
CREATE INDEX u ON dbo.Users (TotalVotes) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE (u.DownVotes + u.UpVotes) > 1000;
Remember that this is the query that has things backwards and doesn’t use the index on our computed column, but look what happened to the query plan:
me without makeup
Querying a completely different index results in a plan that SQL Server can’t parallelize because of the function.
Fifth: Column store indexes are weird with them. There’s an odd bit of a matrix, too.
Anything before SQL Server 2017, no dice
Any nonclustered columnstore index through SQL Server 2019, no dice
For 2017 and 2019, you can create a clustered columnstore index on a table with a computed column as long as it’s not persisted
--Works
CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date));
CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore;
--Doesn't work
CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date));
CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date);
--Clean!
DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore;
--Doesn't work, but throws a misleading error
CREATE TABLE clustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED);
CREATE CLUSTERED COLUMNSTORE INDEX c ON dbo.clustered_columnstore;
--Still doesn't work
CREATE TABLE nonclustered_columnstore (id int, some_date datetime, next_date datetime, diff_date AS DATEDIFF(MILLISECOND, some_date, next_date) PERSISTED);
CREATE NONCLUSTERED COLUMNSTORE INDEX n ON dbo.nonclustered_columnstore(id, some_date, next_date, diff_date);
--Clean!
DROP TABLE dbo.clustered_columnstore, dbo.nonclustered_columnstore;
General Uses
The most general use for computed columns is to materialize an expression that a query has to filter on, but that wouldn’t otherwise be able to take advantage of an index to locate rows efficiently, like the UpVotes and DownVotes example above.
Even with an index on UpVotes, DownVotes, nothing in your index keeps track of what row values added together would be.
SQL Server has to do that math every time the query runs and then filter on the result. Sometimes those expressions can be pushed to an index scan, and other times they need a Filter operator later in the plan.
Consider a query that inadvisably does one of these things:
function(column) = something
column + column = something
column + value = something
value + column = something
column = case when …
value = case when column…
convert_implicit(column) = something
As long as all values are known ahead of time — meaning they’re not a parameter, variable, or runtime constant like GETDATE() — you can create computed columns that you can index and make searches really fast.
Take this query and index as an example:
SELECT c = COUNT_BIG(*) FROM dbo.Posts AS p WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 9;
CREATE INDEX p ON dbo.Posts(CreationDate, LastActivityDate) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
The best we can do is still to read every row via a scan:
still not good
But we can fix that by computing and indexing:
ALTER TABLE dbo.Posts ADD ComputedDiff AS DATEDIFF(YEAR, CreationDate, LastActivityDate);
CREATE INDEX p ON dbo.Posts(ComputedDiff) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
And now our query plan is much faster, without needing to go parallel, or more parallel, to get faster:
improvement!
SQL Server barely needs to flinch to finish that query, and we get an actually good estimate to boot.
Crappy Limitations
While many computed columns can be created, not all can be indexed. For example, something like this would be lovely to have and to have indexed:
ALTER TABLE dbo.Users ADD RecentUsers AS DATEDIFF(DAY, LastAccessDate, SYSDATETIME());
CREATE INDEX u ON dbo.Users (RecentUsers);
While the column creation does succeed, the index creation failed:
Msg 2729, Level 16, State 1, Line 177
Column ‘RecentUsers’ in table ‘dbo.Users’ cannot be used in an index or statistics or as a partition key because it is non-deterministic.
You also can’t reach out to other tables:
ALTER TABLE dbo.Users ADD HasABadge AS CASE WHEN EXISTS (SELECT 1/0 FROM dbo.Badges AS b WHERE b.UserId = Id) THEN 1 ELSE 0 END;
SQL Server doesn’t like that:
Msg 1046, Level 15, State 1, Line 183
Subqueries are not allowed in this context. Only scalar expressions are allowed.
There are other, however these are the most common disappointments I come across.
Some of the things that computed columns fall flat with are things we can remedy with indexed views, but boy howdy are there a lot of gotchas.
We’ll talk about those tomorrow!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
For all the good indexes do, sometimes you just don’t need them to cover all of the data in a table for various reasons.
There are a number of fundamentals that you need to understand about them (that any good consultant will tell you about), but I wanna cover them here just in case you had an unfortunate run-in with a less-than-stellar consultant.
First, there are some session-level settings that need to be appropriately applied for them to be considered by the optimizer. This is especially important if you’re putting any logic into a SQL Server Agent job, because it uses the wrong settings for some reason.
Here are the correct settings:
QUOTED_IDENTIFIER ON
ANSI_NULLS ON
ANSI_PADDING ON
ANSI_WARNINGS ON
ARITHABORT ON
CONCAT_NULL_YIELDS_NULL ON
NUMERIC_ROUNDABORT OFF
Second, you need to be careful about parameterized queries. If your filtered index and query looks like this:
CREATE INDEX u ON dbo.Users(Reputation) WHERE Reputation > 100000;
SELECT c = COUNT_BIG(*) FROM dbo.Users AS u WHERE u.Reputation > @Reputation;
The optimizer will not use your filtered index, because it has to pick a safe and cache-able plan that works for any input to the @Reputation parameter (this goes for local variables, too).
To get around this, you can use:
Recompile hint
Literal value
Potentially unsafe dynamic SQL
Third, you need to have the columns in your filtering expression be somewhere in your index definition (key or include) to help the optimizer choose your index in some situations.
Let’s say you have a filtered index that looks like this:
CREATE INDEX u ON dbo.Users(DisplayName) WHERE Reputation > 100000;
As thing stand, all the optimizer knows is that the index is filtered to Reputation values over 100k. If you need to search within that range, like 100k-200k, or >= 500k, it has to get those values from somewhere, and it has the same options as it does for other types of non-covering indexes:
Ignore the index you thoughtfully created and use another index
Use a key lookup to go back to the clustered index to filter specific values
General Uses
The most common uses that I see are:
Indexing for soft deletes
Indexing unique values and avoiding NULLs
Indexing for hot data
Indexing skewed data to create a targeted histogram
There are others, but one thing to consider when creating filtered indexes is how much of your data will be excluded by the definition.
If more than half of your data is going to end up in there, you may want to think hard about what you’re trying to accomplish.
Another potential use that I sometimes find for them is using the filter to avoid needing an overly-wide index key.
Let’s say you have a super important query that looks like this:
SELECT
u.DisplayName,
TotalScore =
SUM(p.Score)
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.AcceptedAnswerId > 0
AND p.ClosedDate IS NULL
AND p.Score > @Score
AND p.OwnerUserId = @OwnerUserId
ORDER BY TotalScore DESC;
You’re looking at indexing for one join clause predicate and four additional where clause predicates. Do you really want five key columns in your index? No?
How about this?
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score)
INCLUDE
(PostTypeId, AcceptedAnswerId, ClosedDate)
WHERE
(PostTypeId = 1 AND AcceptedAnswerId > 0 AND ClosedDate IS NULL)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
This will allow your query to pre-seek to the the literal value predicates, and then evaluate the parameterized predicates in the key of the index.
Crappy Limitations
There are lots of things you might want to filter an index on, like an expression. But you can’t.
I think one of the best possible use cases for a filtered index that is currently not possible is to isolate recent data. For example, I’d love to be able to create a filtered index like this:
CREATE INDEX u ON dbo.Users(DisplayName) WHERE CreationDate > DATEADD(DAY, -30, CONVERT(date, SYSDATETIME()));
So I could just just isolate data in the table that was added in the last 30 days. This would have a ton of applications!
But then the index would have to be self-updating, churning data in and out on its own.
For something like that, you’ll need a computed column. But even indexing those can be tricky, so we’ll talk about those tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.