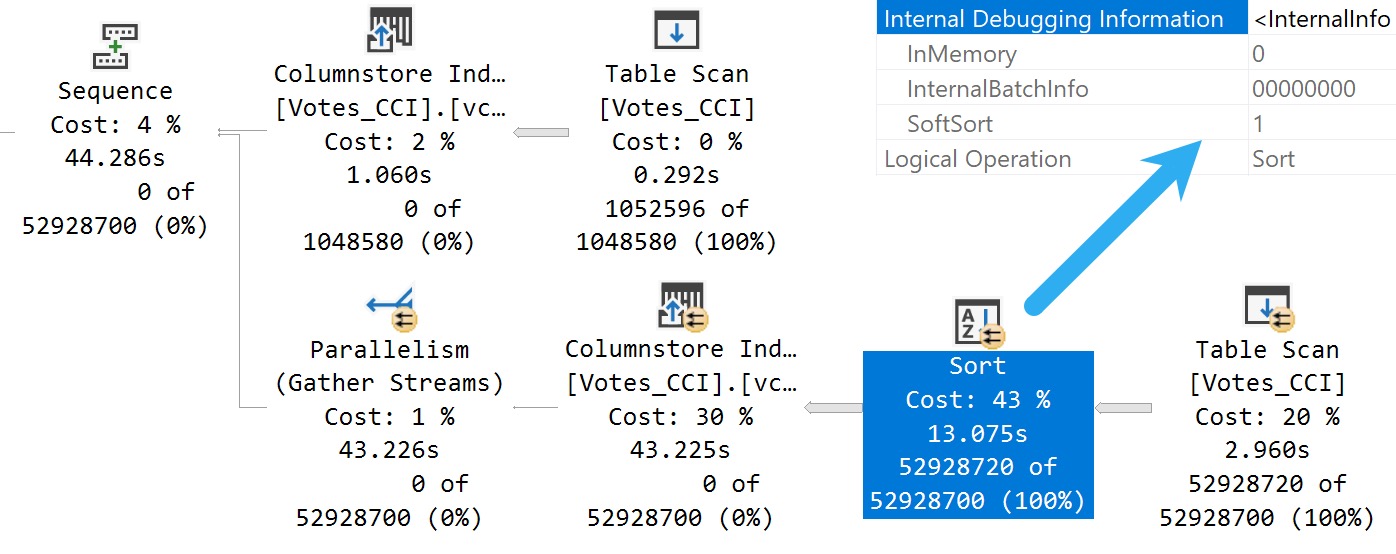
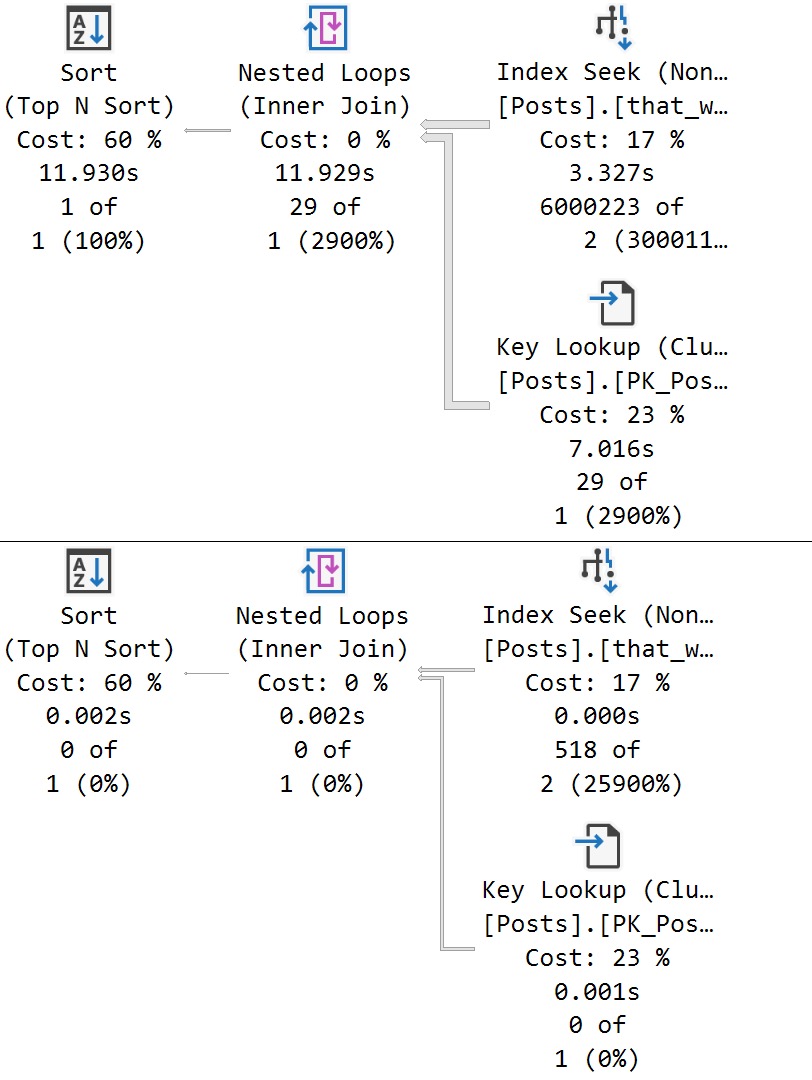
Connections
When one thinks of effective communicators, indexes aren’t usually at the top of the list. And for good reason!
They’re more the strong, silent type. Like Gary Cooper, as a wiseguy once said. But they do need to talk to each other, sometimes.
For this post, I’m going to focus on tables with clustered indexes, but similar communication can happen with the oft-beleaguered heap tables, too.
Don’t believe me? Follow along.
Clustered
This post is going to focus on a table called Users, which has a bunch of columns in it, but the important thing to start with is that it has a clustered primary key on a column called Id.
Shocking, I know.
CONSTRAINT PK_Users_Id
PRIMARY KEY CLUSTERED
(
Id ASC
)
But what does adding that do, aside from put the table into some logical order?
The answer is: lots! Lots and lots. Big lots (please don’t sue me).
Inheritance
The first thing that comes to my mind is how nonclustered indexes inherit that clustered index key column.
Let’s take a look at a couple examples of that. First, with a couple single key column indexes. The first one is unique, the second one is not.
/*Unique*/
CREATE UNIQUE INDEX
whatever_uq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
/*Not unique*/
CREATE INDEX
whatever_nuq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
For these queries, pay close attention to the where clause. We’re searching on both the AccountId column that is the only column defined in our index, and the Id column, which is the only column in our clustered index.
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_uq)
WHERE u.AccountId = 1
AND u.Id = 1;
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_nuq)
WHERE u.AccountId = 1
AND u.Id = 1;
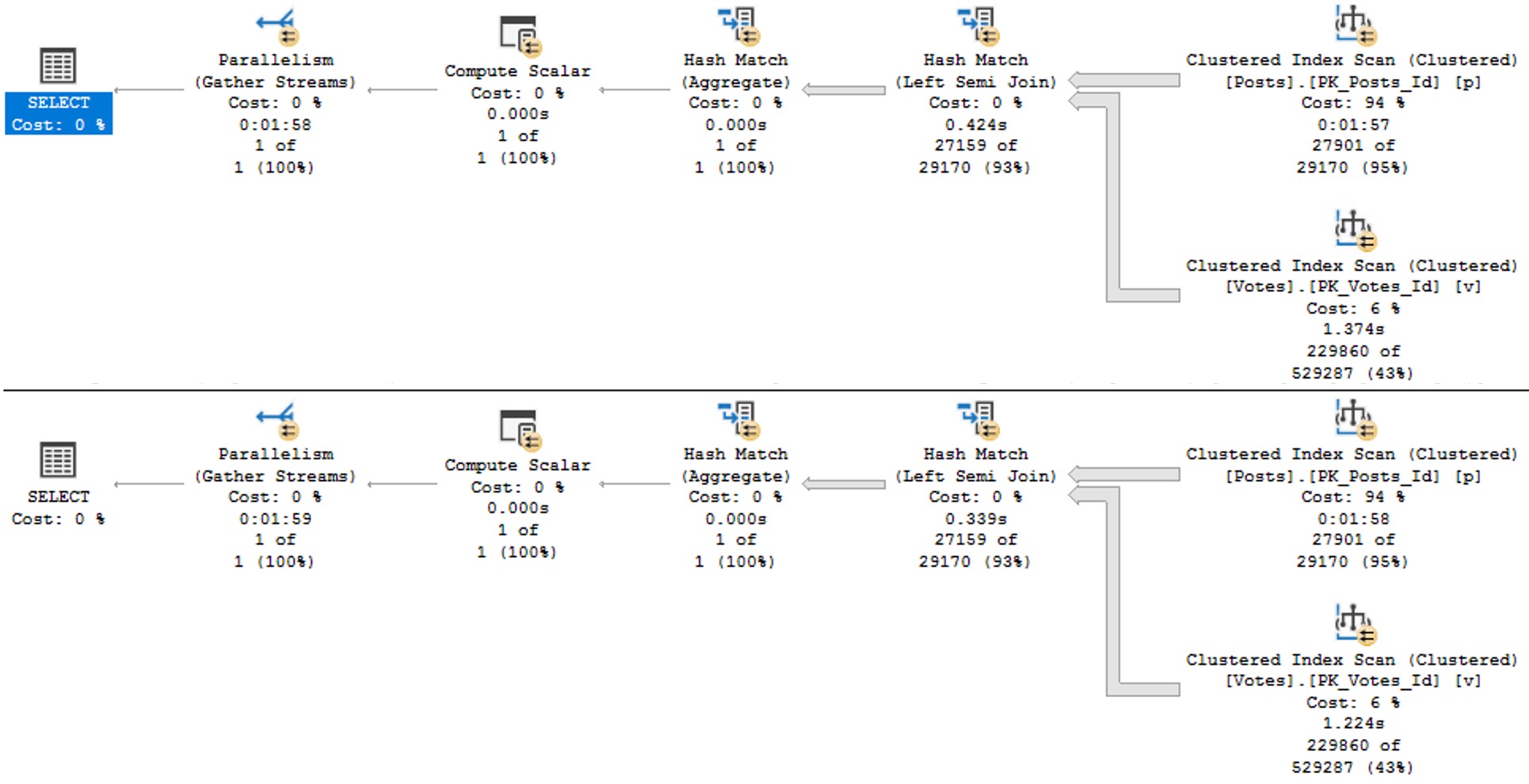
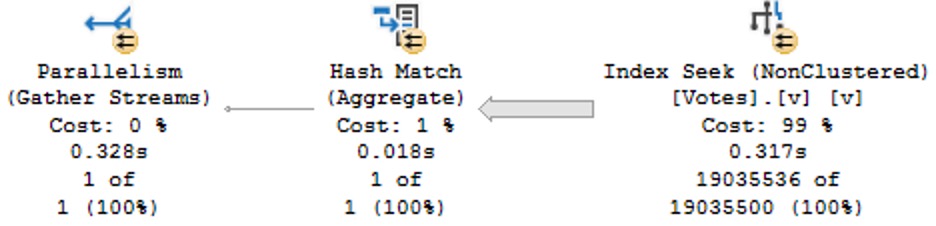
The query plans are slightly different in how the searches can be applied to each index.
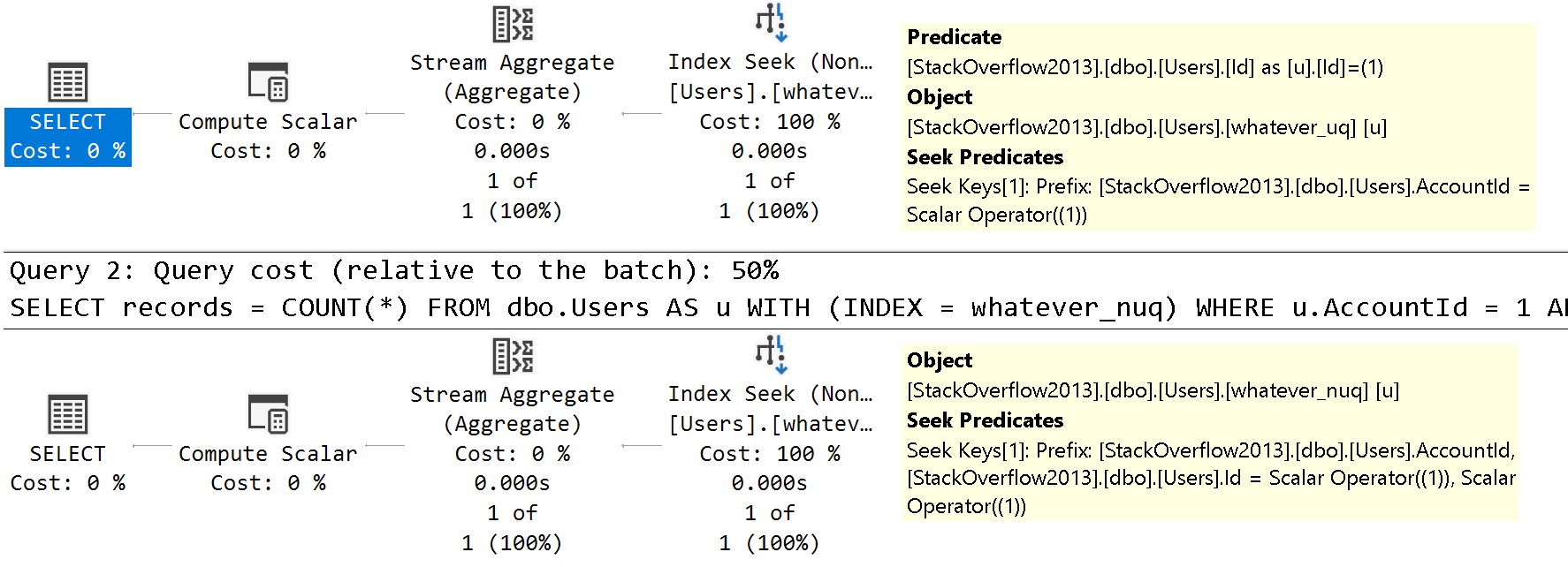
See the difference?
- In the unique index plan, there is one seek predicate to
AccountId, and one residual predicate onId - In the non-unique index plan, there are two seeks, both to
AccountIdand toId
The takeaway here is that unique nonclustered indexes inherit clustered index key column(s) are includes, and non-unique nonclustered indexes inherit them as additional key columns.
Fun!
Looky, Looky
Let’s create two nonclustered indexes on different columns. You know, like normal people. Sort of.
I don’t usually care for single key column indexes, but they’re great for simple demos. Remember that, my lovelies.
CREATE INDEX
l
ON dbo.Users
(LastAccessDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
c
ON dbo.Users
(CreationDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
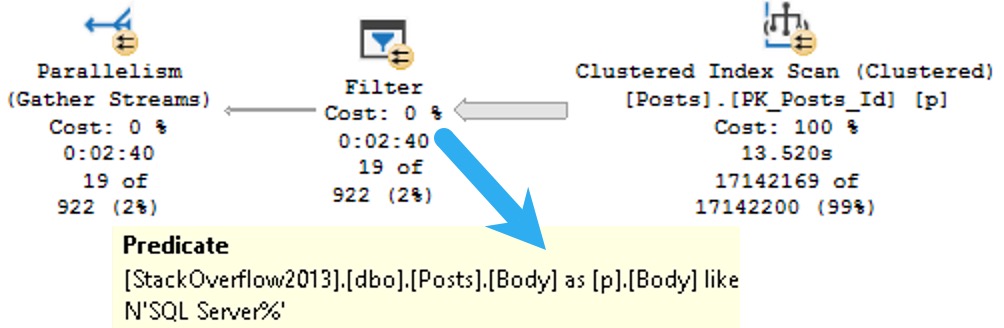
How will SQL Server cope with all that big beautiful index when this query comes along?
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
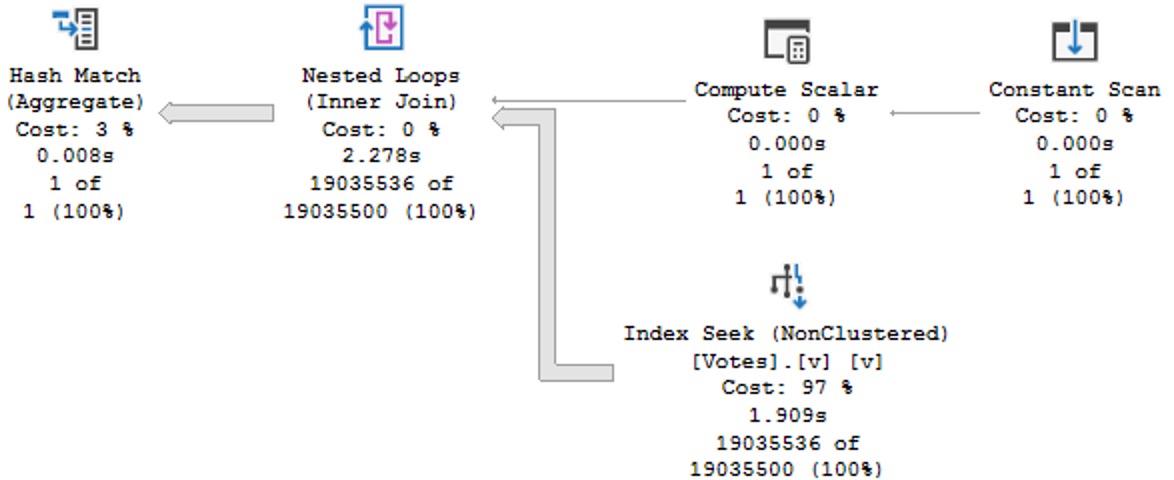
How about this bold and daring query plan?

SQL Server joins two nonclustered indexes together on the clustered index column that they both inherited. Isn’t that nice?
Danes
More mundanely, this is the mechanism key lookups use to work, too. If we change the last query a little bit, we can see a great example of one.
SELECT
u.*
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
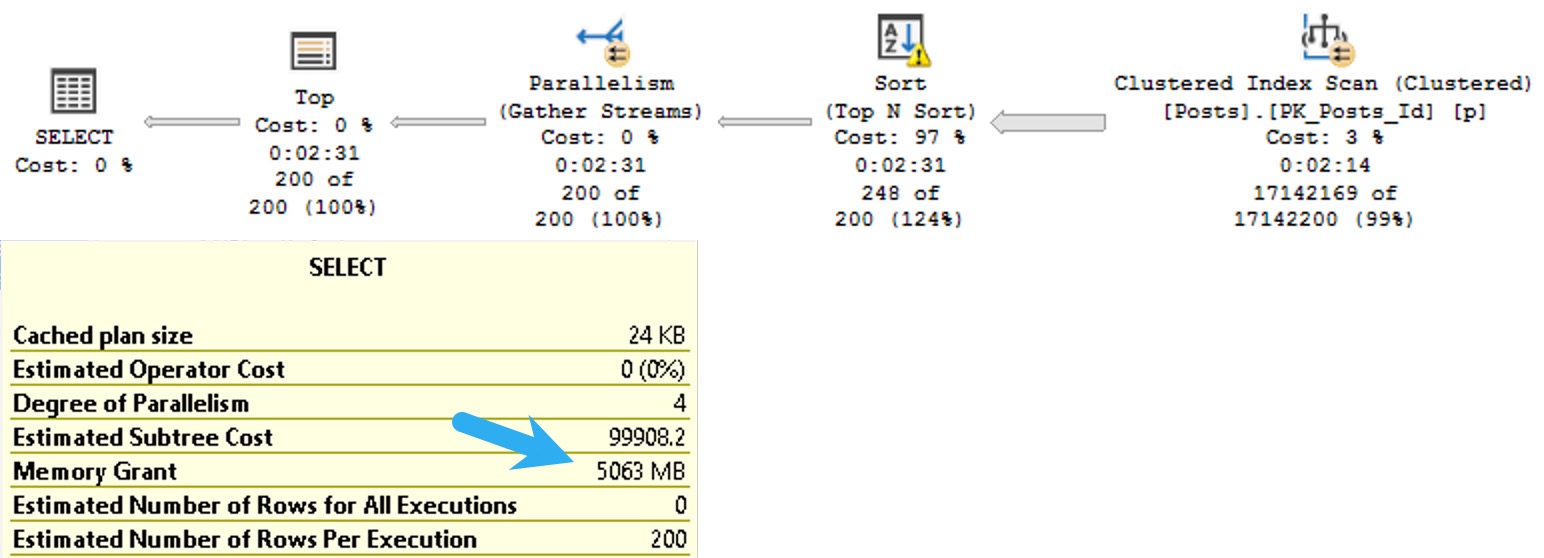
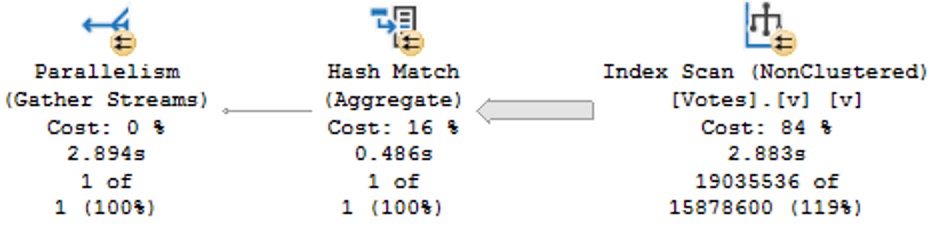
Selecting all the columns from the Users table, we get a different query plan.

The tool tip pictured above is detail from the Key Lookup operator. From the top down:
- Predicate is the additional search criteria that we couldn’t satisfy with our index on Last Access Date
- Object is the index being navigated (clustered primary key)
- Output list is all the columns we needed from the index
- Seek Predicates define the relationship between the clustered and nonclustered index, in this case the Id column
And this is how indexes talk to each other in SQL Server. Yay.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.