I try to set aside money to use on hardware every year, and this year I chose to grab a powerhouse laptop.
The desktop that I built a few years back was starting to feel a little bit creaky. It was easier to buy a better video card and convert it into a gaming rig than try to update various pieces to modernize it.
I’ve long been a fan of ThinkPads, especially the P series of workstations. I’ve got a P51 right now, which I use for general stuff. It’s a powerful laptop, and it was great to travel with and still be able to write and run demos on. Where things get a little trickier is recording/streaming content. If I run any extra spicy demos on here, it impacts everything. Recording and streaming software has to share.
When I had to do that stuff, I used my desktop for demos. This new laptop serves two purposes: it’s a backup in case anything happens to my main laptop, and it’s where I can safely build demos. And hey, maybe someday It’ll be my main laptop, and I’ll have an even crazier laptop for demos.
Eyeball
While watching the Lenovo site for sales, one came along that I couldn’t say no to. I ended up getting about $8500 worth of computer for a shade under $5000.
What’s under the hood?
garbanzo!
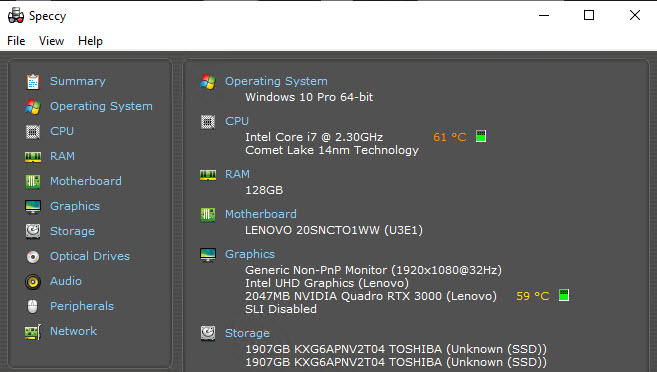
Yes, that is a laptop with 128GB of RAM, and a decent enough graphics card to process video if need be.
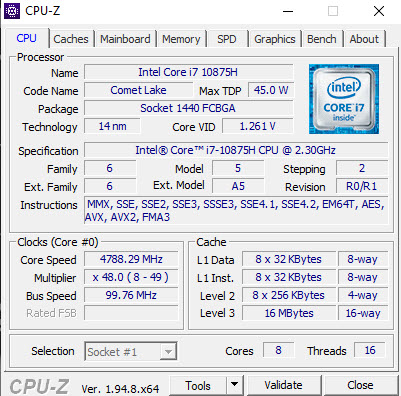
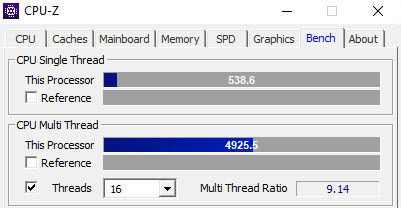
Benched
As far as benchmarks go, this thing is plenty speedy.
zoom zoomtesting, testing
This is great for a laptop. No complaints here.
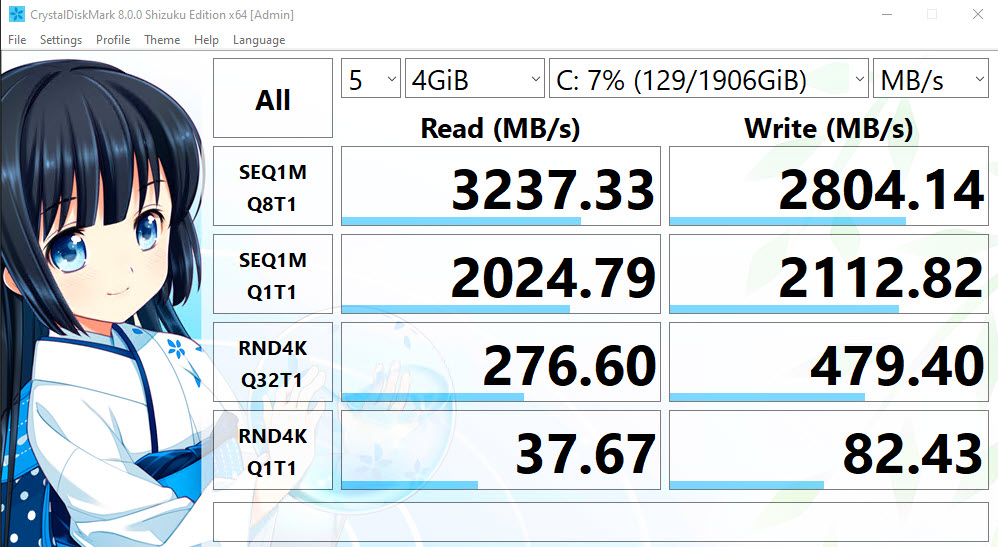
The storage is also pretty sweet.
ALL THE IOPS
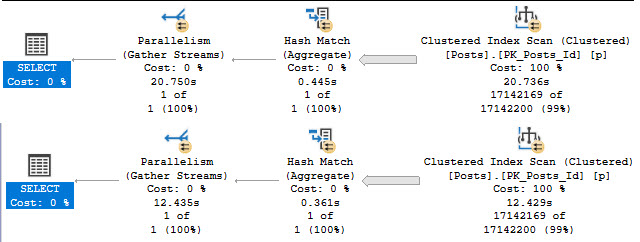
Comparing my P51 storage to the new P17 storage:
1-2, 1-2
I can read the Posts table into memory about 8 seconds faster on the new laptop. Pretty sweet!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Every action has some latency attached to it. Depending on how far you have to go, it could be a lot or a little.
And of course, it also depends on some situations you might run into along the way.
That’s one reason why batch mode can introduce such a performance improvement: CPU instructions are run on batches of rows at a time local to the CPU, rather than a single row at a time. Less fetching is generally a good thing. Remember all those things they told you about cursors and RBAR?
For years, I’ve been sending people over to this post by Jeff Atwood, which does a pretty good job of describing those things.
But you know, I need something a little more specific to SQL Server, and using a slightly different metric: We’re gonna assign $Query Bucks$ to those latencies.
After all, time is money.
Gold Standard
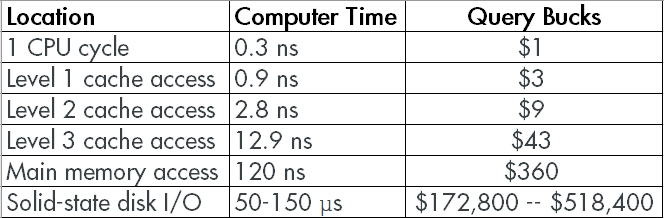
Using a similar formula to Jeff’s, let’s look at how expensive it gets once you cross from memory to disk.
mucho dinero
See the end there, when you jump from nanoseconds to microseconds? At those prices, you start to understand why people like me tell you to solve problems with more memory instead of faster disks. Those numbers are for local storage, of course, and main memory is still leaving Road Runner clouds around it.
If you’re on a SAN — and I don’t mean that SAN disks are slower; they’re not — you have something else to think about.
What I mean is the component in between that can be a real problem: The N in SAN. The Network.
just a little bit
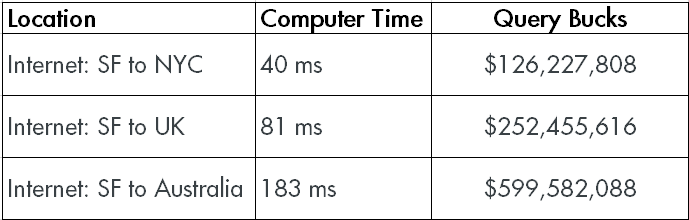
If you add latency in just the milliseconds, costs pretty quickly jump up into numbers that’d make athletes blush. And if you’ve ever seen those 15 second I/O warnings in the error log…
This is where a lot of people under-provision themselves into nightmare. 10Gb Ethernet connections can move data fairly quickly, at around 1.2 GB/s. Which is great for data that’s easily accounted for in 100s of MB. It’s less great for much bigger data, and it’s worse when there’s a lot of other traffic on the same network.
Sensitivity
Competition for these resources, which is really common for database workloads that often have multiple queries all reading and writing data simultaneously, can take what would be an otherwise fine SAN and make it look like a tarpit.
You have to be really careful about these things, and how you choose to address them when you’re dealing with SQL Server.
Standard Edition is in particularly rough shape, with the buffer pool being a laughable 128GB. In order to keep things tidy, your indexes really need to be spot on, so you don’t have unnecessary things ending up there.
The more critical a workload is, the more you have riding on getting things right, which often means getting these numbers as low as possible.
Hardware that’s meant to help businesses consolidate isn’t always set up (or designed) to put performance first. Once you start attaching prices to those decisions that show how much time they can cost your workloads is a good way to start making better decisions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
My Dear Friend™ Sean recently wrote a post talking about how people are doing index maintenance wrong. I’m going to go a step further and talk about how the method your index maintenance scripts use to evaluate fragmentation is wrong.
If you look at how the script you use to decide whether or not you’re going to rebuild indexes works, and this goes for maintenance plans, too (I ran PROFILER LONG LIVE PROFILER GO TEAM PROFILER to confirm the query), you’ll see they run a query against dm_db_index_physical_stats.
All of the queries use the column avg_fragmentation_in_percent to measure if your index needs to be rebuilt. The docs (linked above) for that column have this to say:
He cried
It’s measuring logical fragmentation. Logical fragmentation is when pages are out of order.
If you’re the kind of person who cares about various caches on your server, like the buffer pool or the plan cache, then you’d wanna measure something totally different. You’d wanna measure how much free space you have on each page, because having a bunch of empty space on each page means your data will take up more space in memory when you read it in there from disk.
You could do that with the column avg_page_space_used_in_percent.
BUT…
Oops
Your favorite index maintenance solution will do you a favor and only run dm_db_index_physical_stats in LIMITED mode by default. That’s because taking deeper measurements can be rough on a server with a lot of data on it, and heck, even limited can run for a long time.
But if I were going to make the decision to rebuild an index, this is the measurement I’d want to use. Because all that unused space can be wasteful.
The thing is, there’s not a great correlation between avg_fragmentation_in_percent being high, and avg_page_space_used_in_percent.
Local Database
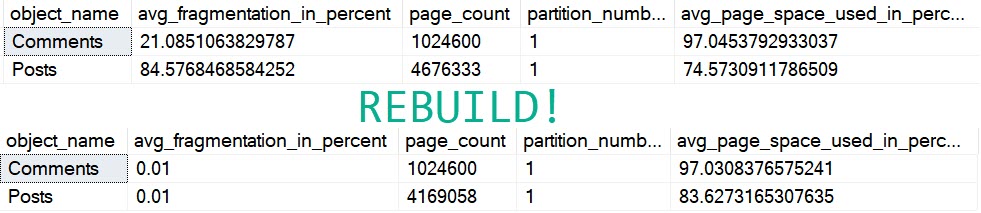
When looking at fragmentation in my copy of the Stack Overflow 2013 database:
Scum
Both of those tables are fragmented enough to get attention from a maintenance solution, but rebuilding only really helps the Posts table, even though we rebuilt both.
On the comments table, avg_page_space_used_in_percent goes down a tiny bit, and Posts gets better by about 10%.
The page count for Comments stays the same, but it goes down by about 500k for Posts.
This part I’m cool with. I’d love to read 500k less pages, if I were scanning the entire table.
But I also really don’t wanna be scanning the entire table outside of reporting or data warehouse-ish queries.
If we’re talking OLTP, avoiding scanning large tables is usually worthwhile, and to do that we create nonclustered indexes that help our queries find data effectively, and write queries with clear predicates that promote the efficient use of indexes.
Right?
Right.
Think About Your Maintenance Settings
They’re probably at the default of 5% and 30% for reorg and rebuild thresholds. Not only are those absurdly low, but they’re not even measuring the right kind of fragmentation. Even at 84% “fragmentation”, we had 75% full pages.
That’s not perfect, but it’s hardly a disaster.
Heck, you’ve probably been memed into setting fill factor lower than that to avoid fragmentation.
Worse, you’re probably looking at every table >1000 pages, which is about 8 MB.
If you have trouble reading and keeping 8 MB tables in memory, maybe it’s time to go shopping.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
But the bottom line is this: If the automatic and intelligent query tuning features are that powerful, then giving Standard Edition either a 256GB buffer pool cap, or a buffer pool cap that scales with CPU licensing spend still won’t make it competitive, because hardware isn’t solving the kind of problems that those features do.
If they’re not, they shouldn’t be Enterprise only. Clearly hardware is the differentiator.
Increasing the buffer pool limit is a free choice
Microsoft gave away most of the important programmability features with 2016 SP1 to Standard Edition, and they’re giving up TDE in 2019.
Those are features that cost real human time to develop, support, and maintain. A larger buffer pool costs nothing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.