Mediation
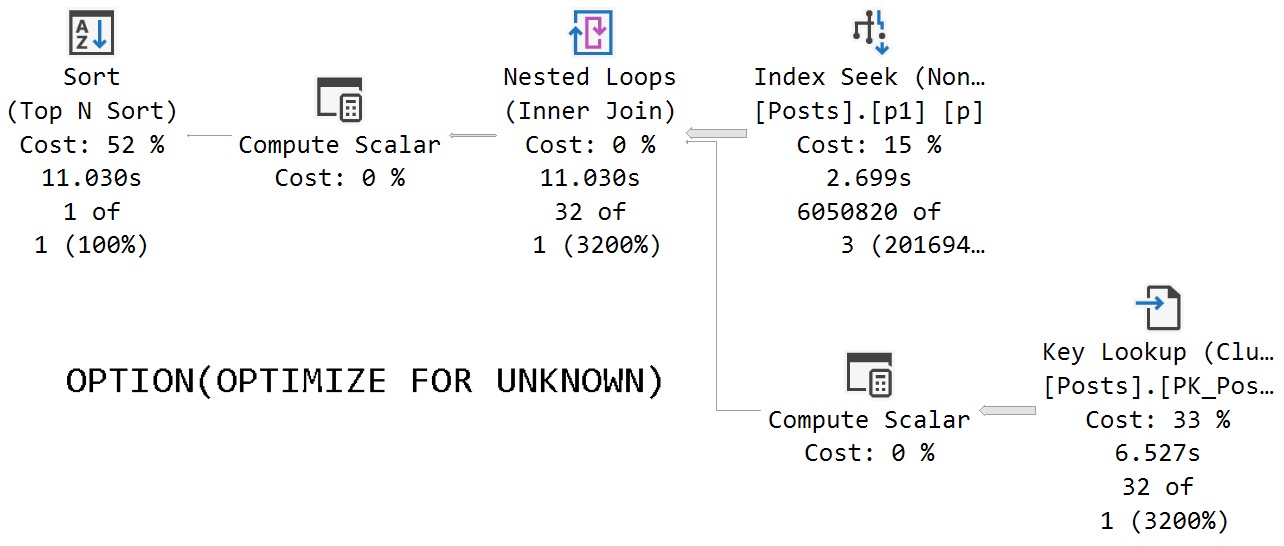
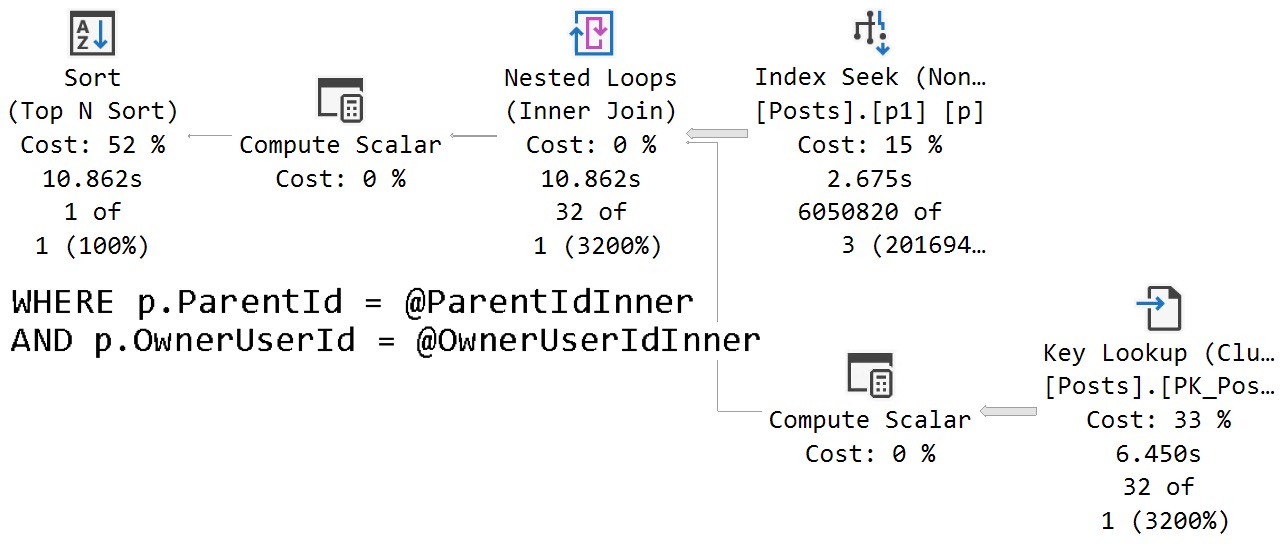
The really annoying thing about foreign keys is that you can’t do anything to affect the query plans SQL Server uses to enforce them.
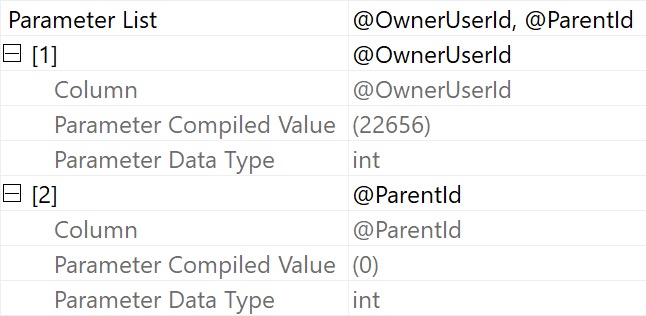
My good AND dear friend Forrest ran into an issue with them that I’ve seen played out at dozens of client sites. Sometimes there are actually foreign keys that don’t have indexes to help them, but even when there are, SQL Server’s optimizer doesn’t always listen to reason, or other cardinality estimation issues are at play. Some can be fixed, and some can’t.
When they can’t, sometimes implementing triggers which are more under your control can be used in place of foreign keys.
The following code isn’t totally suitable for production, but is good enough to illustrate examples.
If you need production-ready code, hit the link at the end of the post to schedule a sales call.
Setup
I’m going to use some slightly modified code from Forrest’s post linked above, since that’s what I started with to see if the foreign key issue still presents in SQL Server 2022 under compatibility level 160.
It does! So. Progress, right? Wrong.
CREATE TABLE
dbo.p
(
id int
PRIMARY KEY,
a char(1),
d datetime DEFAULT SYSDATETIME()
);
CREATE TABLE
dbo.c
(
id int
IDENTITY
PRIMARY KEY,
a varchar(5),
d datetime DEFAULT SYSDATETIME(),
pid int,
INDEX nc NONCLUSTERED(pid)
);
INSERT
dbo.p WITH(TABLOCKX)
(
id,
a
)
SELECT TOP (1000000)
ROW_NUMBER() OVER
(
ORDER BY
(SELECT 1/0)
),
CHAR(m.severity + 50)
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
INSERT
dbo.c WITH(TABLOCKX)
(
a,
pid
)
SELECT TOP (1100000)
REPLICATE
(
CHAR(m.severity + 50),
5
),
ROW_NUMBER() OVER
(
ORDER BY
(SELECT 1/0)
) % 1000000 + 1
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
For Fun
With the boring stuff out of the way, let’s skip to how to set up triggers to replace foreign keys.
For reference, this is the foreign key definition that we want to replicate:
ALTER TABLE
dbo.c
ADD CONSTRAINT
fk_d_up
FOREIGN KEY
(pid)
REFERENCES
dbo.p (id)
ON DELETE CASCADE
ON UPDATE CASCADE;
While it’s a bit contrived to have an update cascade from what would be an identity value for most folks, we’re gonna run with it here for completeness.
Here at Darling Data we care about completion.
Inserts
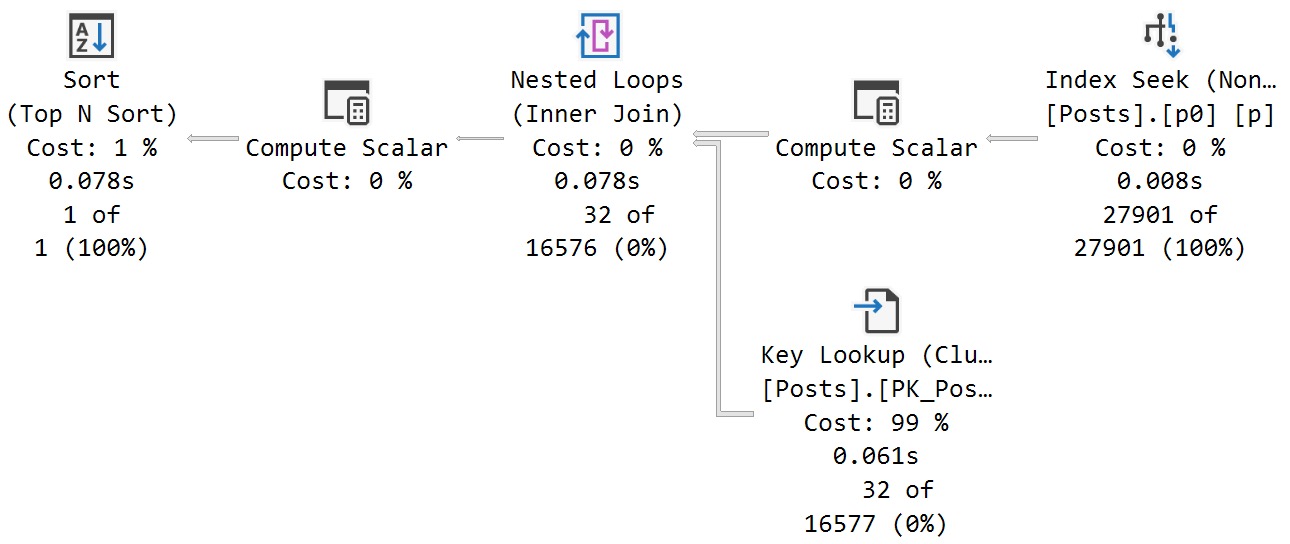
I’m a big fan of instead of insert triggers for this, because they take a shortcut around all the potential performance ramifications of letting a thing happen and checking it afterwards.
Now, you’re going to notice that this trigger silently discards rows that would have violated the foreign key. And you’re totally right! But it’s up to you to decide how you want to handle that.
- Ignore them completely
- Log them to a table
- Correct mismatches via lookup tables
Anyway, here’s the basic trigger I’d use, with hints included to illustrate the points from above about you getting control of plan choices.
CREATE OR ALTER TRIGGER
dbo.instead_insert
ON
dbo.c
INSTEAD OF INSERT
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
INSERT
dbo.c
(
a,
pid
)
SELECT
i.a,
i.pid
FROM Inserted AS i
WHERE EXISTS
(
SELECT
1/0
FROM dbo.p AS p WITH(FORCESEEK)
WHERE p.id = i.id
)
OPTION(LOOP JOIN);
END;
Updates
To manage updates, here’s the trigger I’d use:
CREATE OR ALTER TRIGGER
dbo.after_update
ON
dbo.p
AFTER UPDATE
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
UPDATE c
SET
c.pid = i.id
FROM dbo.c AS c WITH(FORCESEEK)
JOIN Inserted AS i
ON i.id = c.id
OPTION(LOOP JOIN);
END;
Deletes
To manage deletes, here’s the trigger I’d use:
CREATE OR ALTER TRIGGER
dbo.after_delete
ON
dbo.p
AFTER DELETE
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
DELETE c
FROM dbo.c AS c WITH(FORCESEEK)
JOIN Inserted AS i
ON i.id = c.id
OPTION(LOOP JOIN);
END;
Common Notes
All of these triggers have some things in common:
- They start by checking to see if any rows actually changed before moving on
- The SET NOCOUNT ON happens after this, because it will interfere with @@ROWCOUNT
- You may need to use the serializable isolation level to fully protect things, which cascading foreign keys use implicitly
- We don’t need to SET XACT ABORT ON because it’s implicitly used by triggers anyway
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.