Microsoft recently published new guidance on setting server level MAXDOP. I hope to help the community by analyzing the new guidance and offering some of my own thoughts on query parallelism.
Line by line
Documentation is meant to be shared after all, so hopefully no one minds if I quote most of it:
Starting with SQL Server 2016 (13.x), during service startup if the Database Engine detects more than eight physical cores per NUMA node or socket at startup, soft-NUMA nodes are created automatically by default. The Database Engine places logical processors from the same physical core into different soft-NUMA nodes.
This is true and one of the bigger benefits of auto soft-NUMA as far as I’ve been able to tell.
The recommendations in the table below are aimed at keeping all the worker threads of a parallel query within the same soft-NUMA node.
SQL Server is not designed to keep all worker threads in a single soft-NUMA node. That might have been true in SQL Server 2008, but it changed in 2012. The only semi-official documentation that I know of is here and I looked into the behavior here. Read through both if you’re interested in how scheduling of parallel worker threads is performed by SQL Server, but I’ll provide a quick summary via example here.
Suppose you have two soft-NUMA nodes of 6 schedulers each and the server just restarted.NUMA node 0 has positions 0-5 and NUMA node 1 has positions 6-11. The global enumerator starts at position 0. If I run a MAXDOP 4 query then the enumerator advances by 4. The parallel workers are allowed in positions 0-3 which means that any four out of six schedulers can be chosen from NUMA node 0. All parallel worker threads are in NUMA node 0 for the first query. Suppose I run another MAXDOP 4 query. The enumerator advances by 4 and the allowed positions are 4-7. That means that any two schedulers can be chosen from NUMA node 0 and any two schedulers can be chosen from NUMA node 1. The worker threads are split over two soft-NUMA nodes even though query MAXDOP is less than the size of the soft-NUMA nodes.
Unless you’re on a server with a single soft-NUMA node it is difficult to guarantee that all worker threads end up on the same soft-NUMA node. I strongly recommend against aiming for that as a goal. There are more details in the “Preventing hard NUMA worker splits” section of this blog post.
This will improve the performance of the queries and distribution of worker threads across the NUMA nodes for the workload. For more information, see Soft-NUMA.
I’ve heard some folks claim that keeping all parallel workers on a single hard NUMA nodes can be important for query performance. I’ve even seen some queries experience reduced performance when thread 0 is on a different hard NUMA node than parallel worker threads. I haven’t heard of anything about the importance of keeping all of a query’s worker threads on a single soft-NUMA node. It doesn’t really make sense to say that query performance will be improved if all worker threads are on the same soft-NUMA node. Soft-NUMA is a configuration setting. Suppose I have a 24 core hard NUMA node and my goal is to get all of a parallel query’s worker threads on a single soft-NUMA node. To accomplish that goal the best strategy is to disable auto soft-NUMA because that will give me a NUMA node size of 24 as opposed to 8. So disabling auto soft-NUMA will increase query performance?
Starting with SQL Server 2016 (13.x), use the following guidelines when you configure the max degree of parallelism server configuration value:
Server with single NUMA node [and] Less than or equal to 8 logical processors: Keep MAXDOP at or below # of logical processors
I don’t understand this guidance at all. If MAXDOP is set to above the number of logical processors then the total number of logical processors is used. This is even mentioned earlier on the same page of documentation. This line is functionally equivalent to “Set MAXDOP to whatever you want”.
Server with single NUMA node [and] Greater than 8 logical processors: Keep MAXDOP at 8
This configuration is only possible with a physical core count between 5 and 8 and with hyperthreading enabled. Setting MAXDOP above the physical core count isn’t recommended by some folks, but I suppose there could be some scenarios where it makes sense. Keeping MAXDOP at 8 isn’t bad advice for many queries on a large enough server, but the documentation is only talking about small servers here.
Server with multiple NUMA nodes [and] Less than or equal to 16 logical processors per NUMA node: Keep MAXDOP at or below # of logical processors per NUMA node
I have never seen an automatic soft-NUMA configuration result in more than 16 schedulers per soft-NUMA node, so this covers all server configurations with more than 8 physical cores. Soft-NUMA scheduler counts per node can range from 4 to 16. If you accept this advice then in some scenarios you’ll need to lower MAXDOP as you increase the number of physical cores per socket. For example, if I have 24 schedulers per socket without hyperthreading then auto soft-NUMA gives me three NUMA nodes of 8 schedulers, so I might set MAXDOP to 8. But if the scheduler count is increased to 25, 26, or 27 then I’ll have at least one soft-NUMA node of 6 schedulers. So I should lower MAXDOP from 8 to 6 because the physical core count of the socket increased?
Server with multiple NUMA nodes [and] Greater than 16 logical processors per NUMA node: Keep MAXDOP at half the number of logical processors per NUMA node with a MAX value of 16
I have never seen an automatic soft-NUMA configuration result in more than 16 schedulers per soft-NUMA node. I believe that this is impossible. At the very least, if it possible I can tell you that it’s rare. This feels like an error in the documentation. Perhaps they were going for some kind of hyperthreading adjustment?
NUMA node in the above table refers to soft-NUMA nodes automatically created by SQL Server 2016 (13.x) and higher versions.
I suspect that this is a mistake and that some “NUMA node” references are supposed to refer to hard NUMA. It’s difficult to tell.
Use these same guidelines when you set the max degree of parallelism option for Resource Governor workload groups.
There are two benefits to using MAXDOP at the Resource Governor workload group level. The first benefit is that it allows different workloads to have different MAXDOP without changing lots of application code. The guidance here doesn’t allow for that benefit. The second benefit is that it acts as a hard limit on query MAXDOP as opposed to the soft limit provided with server level MAXDOP. It may also be useful to know that the query optimizer takes server level MAXDOP into account when creating a plan. It does not do so for MAXDOP set via Resource Governor.
I haven’t seen enough different types of workloads in action to provide generic MAXDOP guidance, but I can share some of the issues that can occur with query parallelism being too low or too high.
What are some of the problems with setting MAXDOP too low?
- Better query performance may be achieved with a higher MAXDOP. For example, a well-written MAXDOP 8 query on a quiet server may simply run eight times as quickly as the MAXDOP 1 version. In some scenarios this is highly desired behavior.
- There may not be enough concurrent queries to get full value out of the server’s hardware without increasing query MAXDOP. Unused schedulers can be a problem for batch workloads that aim to get a large, fixed amount of work done as quickly as possible.
- Row mode bitmap operators associated with hash joins and merge joins only execute in parallel plans. MAXDOP 1 query plans lose out on this optimization.
What are some of the problems with setting MAXDOP too high?
- At some point, throwing more and more parallel queries at a server will only slow things down. Imagine adding more and more cars to an already gridlocked traffic situation. Depending on the workload you may not want to have many active workers per scheduler.
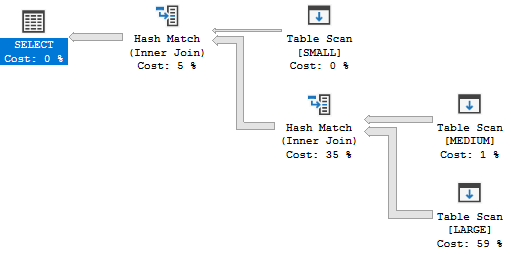
- It is possible to run out of worker threads with many concurrent parallel queries that have many parallel branches each. For example, a MAXDOP 8 query with 20 branches will ask for 160 parallel workers. When this happens parallel queries can get downgraded all the way to MAXDOP 1.
- Row mode exchange operators need to move rows between threads and do not scale well with increased query MAXDOP.
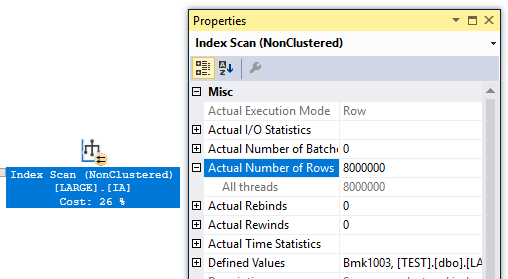
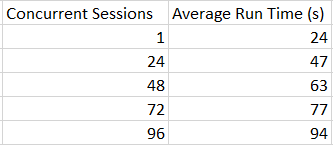
- Some types of row mode exchange operators evenly divide work among all parallel worker threads. This can degrade query performance if even one worker thread is on a busy scheduler. Consider a server with 8 schedulers. Scheduler 0 has two active workers and all other schedulers have no workers. Suppose there is 40 seconds of CPU work to do, the query scales with MAXDOP perfectly, and work is evenly distributed to worker threads. A MAXDOP 4 query can be expected to run in 40/4 = 10 seconds since SQL Server is likely to pick four of the seven less busy schedulers. However, a MAXDOP 8 query must put one of the worker threads on scheduler 0. The work on schedulers 1 – 7 will finish in 40/8 = 5 seconds but the worker thread on scheduler 0 has to yield to the other worker threads. It may take 5 * 3 = 15 seconds if CPU is shared evenly, so in this example increasing MAXDOP from 4 to 8 increases query run time from 10 seconds to 15 seconds.
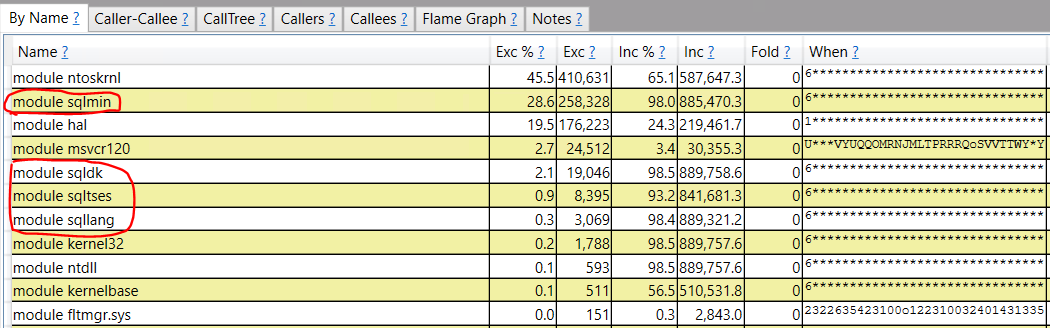
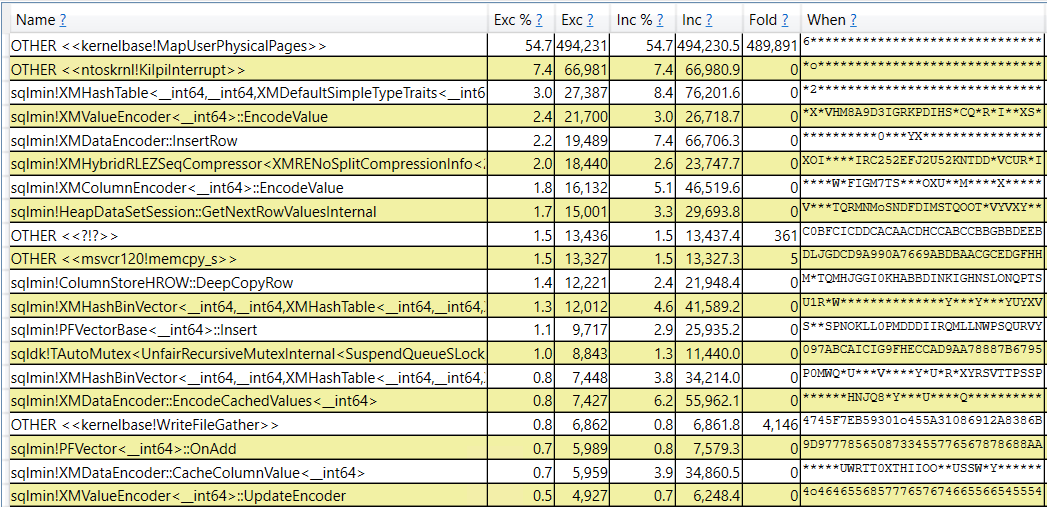
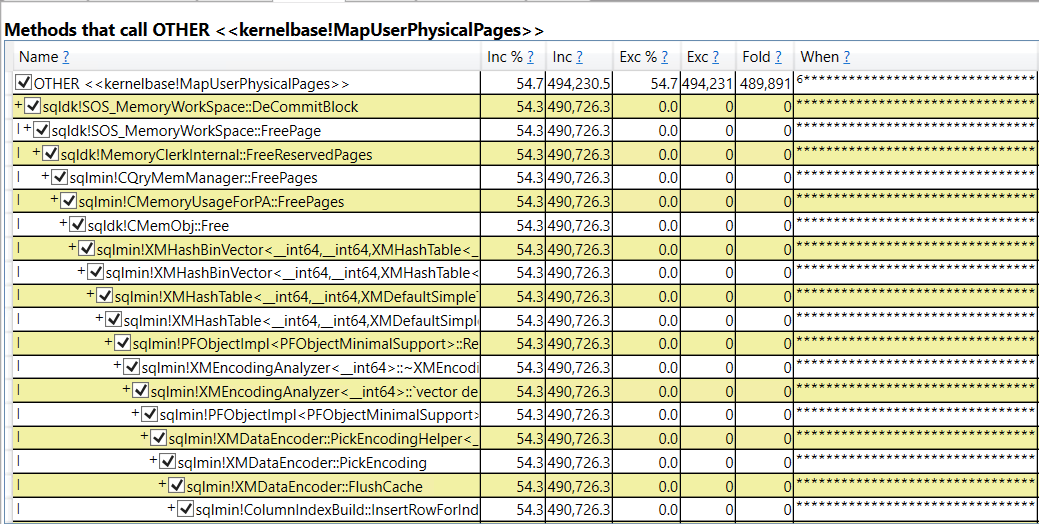
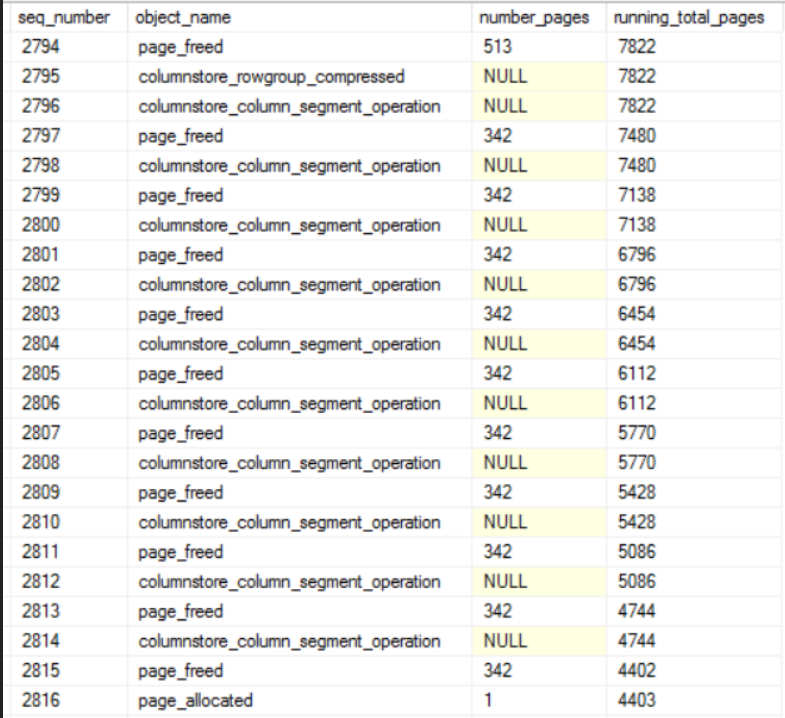
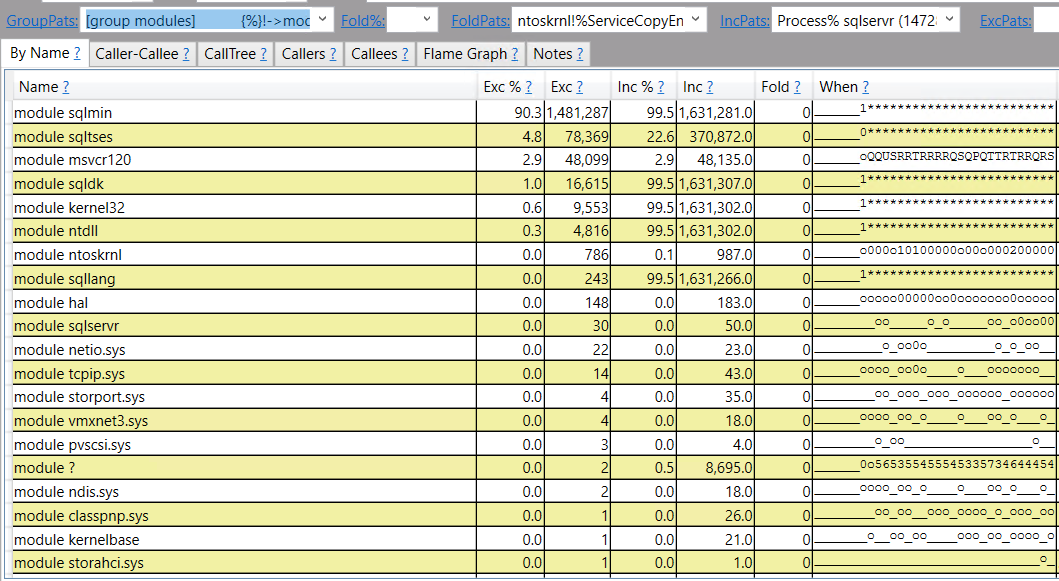
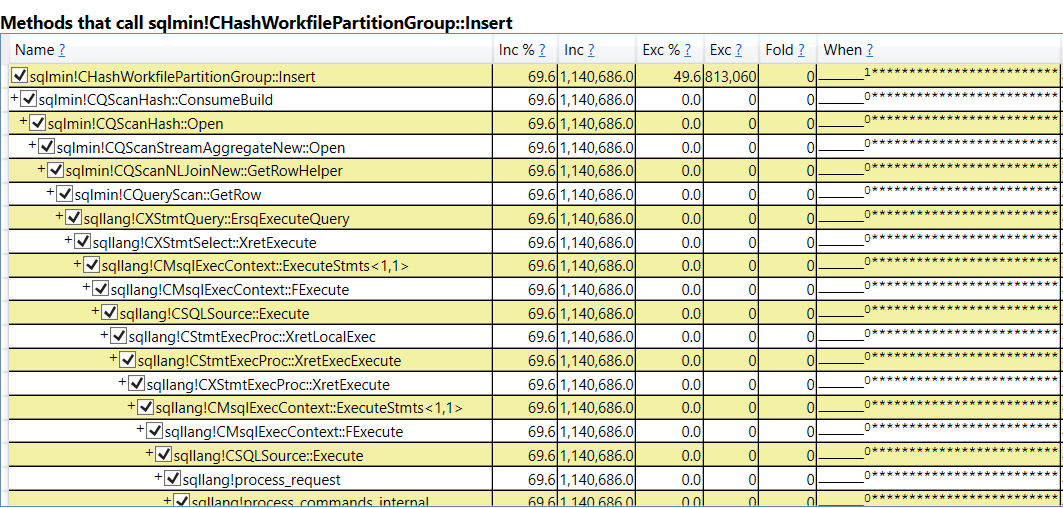
- The query memory grant for parallel inserts into columnstore indexes increases with MAXDOP. If MAXDOP is too high then memory pressure can occur during compression and the SELECT part of the query may be starved for memory.
- The query memory grant for memory-consuming operators on the inner side of a nested loop is often not increased with MAXDOP even though the operator may execute concurrently once on each worker thread. In some uncommon query patterns, increasing MAXDOP will increase the amount of data spilled to tempdb.
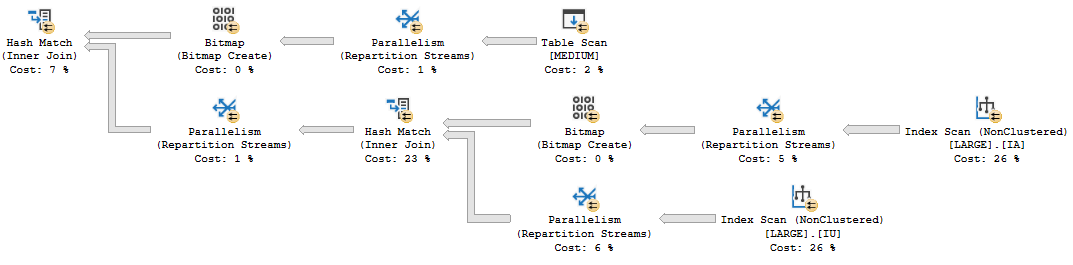
- Increasing MAXDOP increases the number of queries that will have parallel workers spread across multiple hard NUMA nodes. If MAXDOP is greater than the number of schedulers in a hard NUMA node then the query is guaranteed to have split workers. This can degrade query performance for some types of queries.
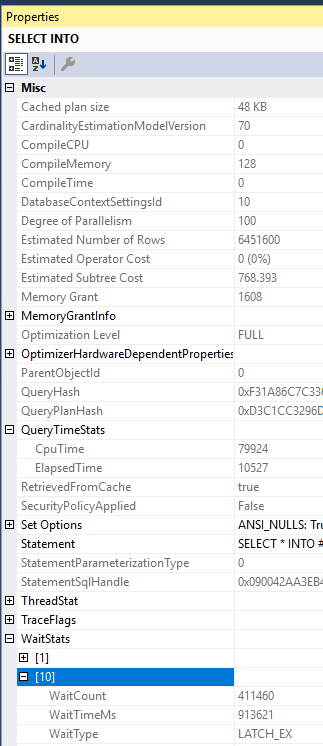
- Worker threads may need to wait on some type of shared resource. Increasing MAXDOP can increase contention without improving query performance. For example, there’s nothing stopping me from running a MAXDOP 100 SELECT INTO, but I certainly do not get 100X of the performance of a MAXDOP 1 query. The problem with the below query is the NESTING_TRANSACTION_FULL latch:
Preventing hard NUMA worker splits
It generally isn’t possible to prevent worker splits over hard NUMA nodes without changing more than server level and query level MAXDOP. Consider a server with 2 hard NUMA nodes of 10 schedulers for each. To avoid a worker split, an administrator might try setting server level MAXDOP to 10, with the idea being that each parallel query spreads its workers over NUMA node 0 or NUMA node 1. This plan won’t work if any of the following occur:
- Any query runs with a query level MAXDOP hint other than 0, 1, 10, or 20.
- Any query is downgraded in MAXDOP but still runs in parallel.
- A parallel stats update happens. The last time I checked these run with a query level MAXDOP hint of 16.
- Something else unexpected happens.
In all cases the enumerator will be shifted and any MAXDOP 10 queries that run after will split their workers. TF 2467 can help, but it needs to be carefully tested with the workload. With the trace flag, as long as MAXDOP <= 10 and automatic soft-NUMA is disabled then the parallel workers will be sent to a single NUMA node based on load. Note that execution context 0 thread can still be on a different hard NUMA node. If you want to prevent that then you can try Resource Governor CPU affinity at the Resource Pool level. Create one pool for NUMA node 0 and one pool for NUMA node 1. You may experience interesting consequences when doing that.
The most reliable method by far is to have a single hard NUMA node, so if you have a VM that fits into a single socket of a VM host and you care about performance then ask your friendly VM administrator for some special treatment.
Final thoughts
I acknowledge that it’s difficult to create MAXDOP guidance that works for all scenarios and I hope that Microsoft continues to try to improve their documentation on the subject. Thanks for reading!
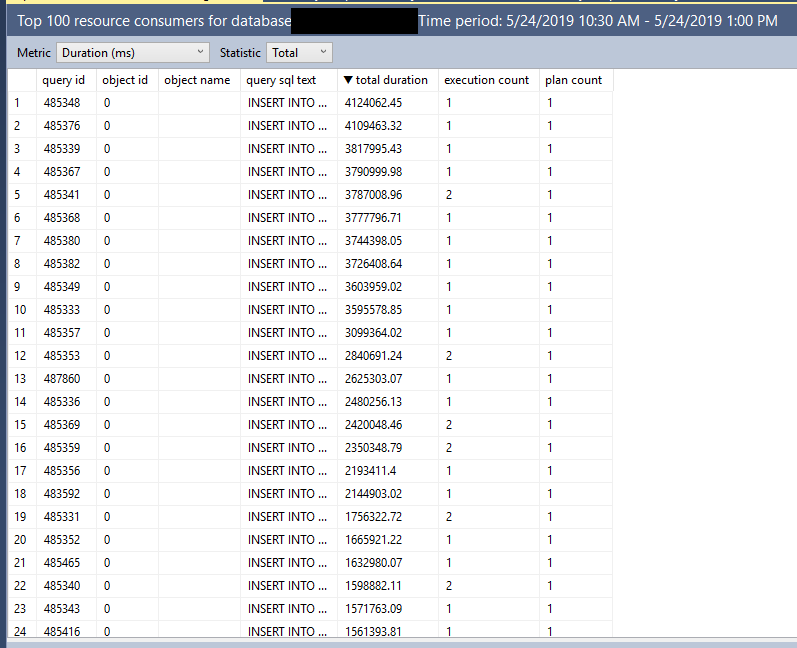
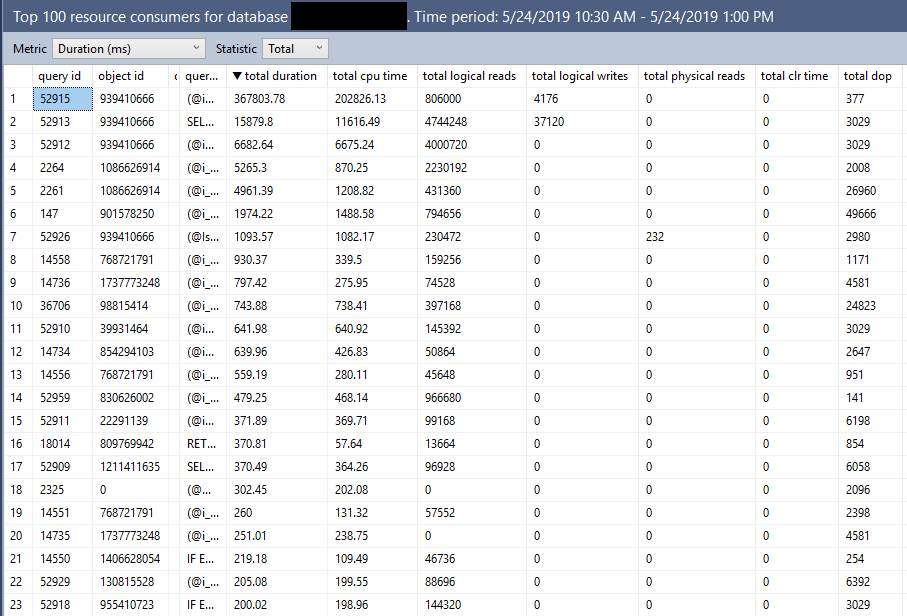
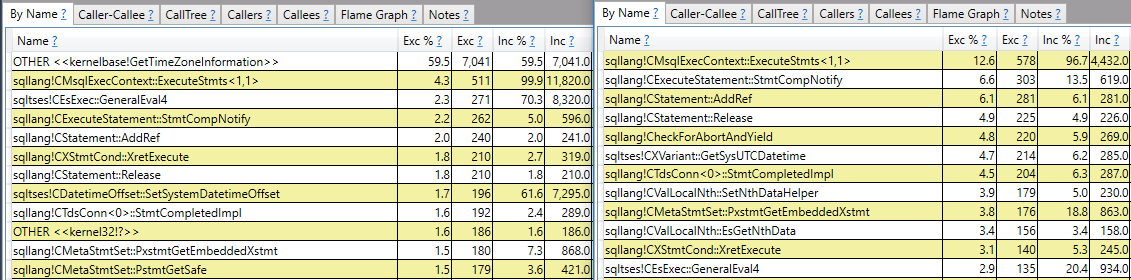
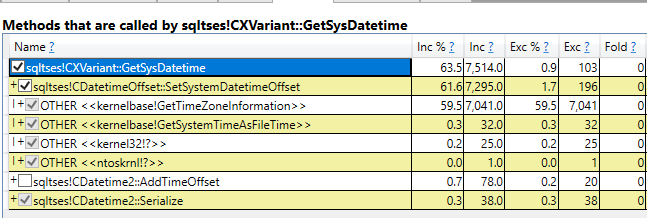
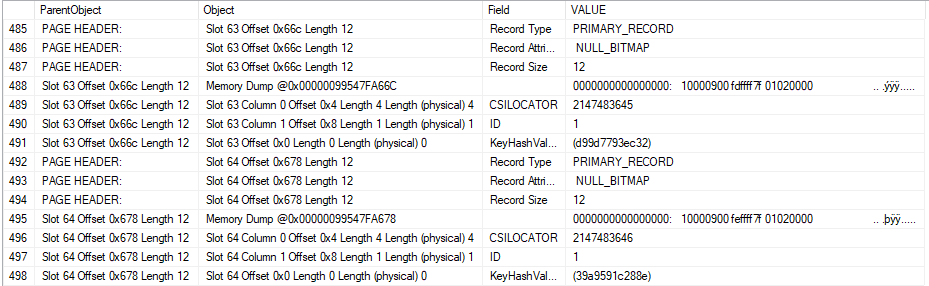
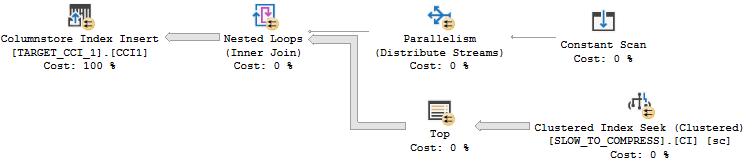



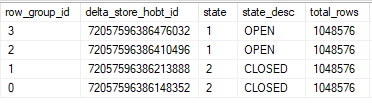
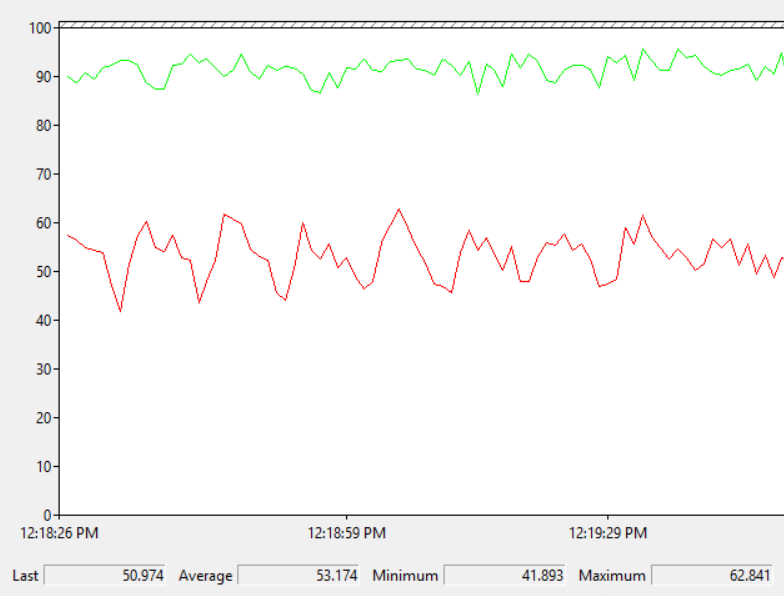
 I set Max Server Memory to 8000 MB and executed two queries with a maximum allowed memory grant of 60% via Resource Governor. The first query finished in about 40 seconds. The second query hasn’t finished after 30 minutes. During those 30 minutes the second query has only used 1184 ms of CPU time. The COLUMNSTORE_BUILD_THROTTLE wait type shows up in
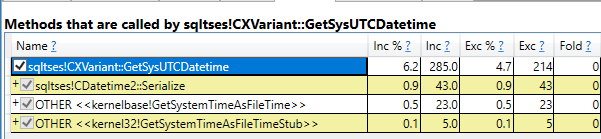
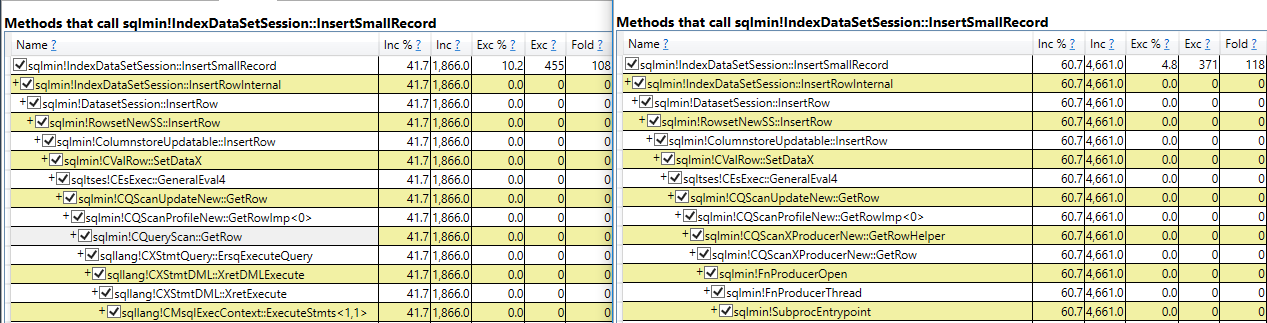
I set Max Server Memory to 8000 MB and executed two queries with a maximum allowed memory grant of 60% via Resource Governor. The first query finished in about 40 seconds. The second query hasn’t finished after 30 minutes. During those 30 minutes the second query has only used 1184 ms of CPU time. The COLUMNSTORE_BUILD_THROTTLE wait type shows up in  Execution context id 2 is waiting on execution context id 1 with a wait type of HTDELETE. Execution context id 1 has a wait type of COLUMNSTORE_BUILD_THROTTLE. I don’t think that this wait is supposed to show up for parallel inserts. It can show up by design when
Execution context id 2 is waiting on execution context id 1 with a wait type of HTDELETE. Execution context id 1 has a wait type of COLUMNSTORE_BUILD_THROTTLE. I don’t think that this wait is supposed to show up for parallel inserts. It can show up by design when