Lawdy
There was a three-part series of posts where I talked about a weird performance issue you can hit with parameterized top. While doing some query tuning for a client recently, I ran across a funny scenario where they were using TOP PERCENT to control the number of rows coming back from queries.
With a parameter.
So uh. Let’s talk about that.
Setup Time
Let’s start with a great index. Possibly the greatest index ever created.
CREATE INDEX whatever
ON dbo.Votes
(VoteTypeId, CreationDate DESC)
WITH
(
MAXDOP = 8,
SORT_IN_TEMPDB = ON
);
GO
Now let me show you this stored procedure. Hold on tight!
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN
SELECT TOP (@top) PERCENT
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
Cool. Great.
Spool Hardy
When we execute the query, the plan is stupid.
EXEC dbo.top_percent_sniffer
@top = 1,
@vtid = 6;
GO

We don’t use our excellent index, and the optimizer uses an eager table spool to hold rows and pass the count to the TOP operator until we hit the correct percentage.
This is the least ideal situation we could possibly imagine.
Boot and Rally
A while back I posted some strange looking code on Twitter, and this is what it ended up being used for (among other things).
getting weird. pic.twitter.com/lRVQQr81Yi
— Erik Darling Data (@erikdarlingdata) February 27, 2021
The final version of the query looks like this:
CREATE OR ALTER PROCEDURE dbo.top_percent_sniffer
(
@top bigint,
@vtid int
)
AS
SET NOCOUNT, XACT_ABORT ON;
BEGIN;
WITH pct AS
(
SELECT
records =
CONVERT(bigint,
CEILING(((@top * COUNT_BIG(*)) / 100.)))
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
)
SELECT
v.*
FROM pct
CROSS APPLY
(
SELECT TOP (pct.records)
v.*
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC
) AS v;
END;
GO
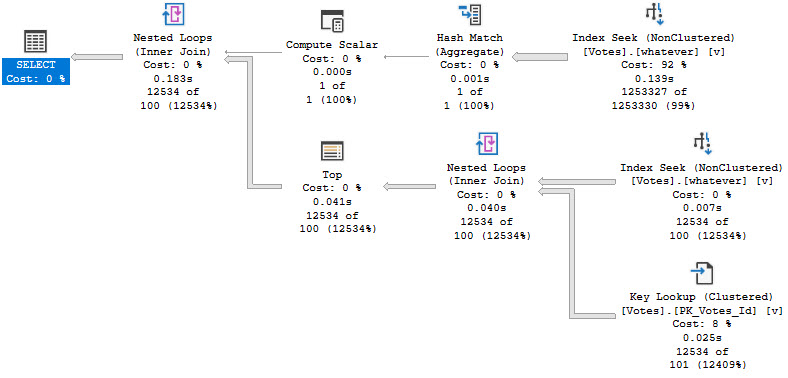
Soul Bowl
This definitely has drawbacks, since the expression in the TOP always gives a 100 row estimate. For large numbers of rows, this plan could be a bad choice and we might need to do some additional tuning to get rid of that lookup.
There might also be occasions when using a column store index to generate the count would be benefit, and the nice thing here is that since we’re accessing the table in two different ways, we could use two different indexes.
But for reliably small numbers of rows, this is a pretty good solution.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “A Parameterization Performance Puzzle With TOP PERCENT in SQL Server”
Comments are closed.