Utility
There are a lot of good reasons to use tablock on your inserts, as long as you can handle the reduced concurrency of a table level lock.
You may get minimal logging here, here. And you may even get parallel inserts. You may even avoid weird compression side effects.
All very good reasons to vie for the affections of tablock hints!
You should do that.
You should try.
Because Sometimes
You may run into oddball scenarios where the results without tablock are better.
For example, I was experimenting with clustered column store temp tables for another post, and I came across this oddity.
Assume two identical inserts, but one has a tablock hint and one doesn’t.
DROP TABLE IF EXISTS #t_cci;
GO
CREATE TABLE #t_cci (UserId INT, VoteTypeId INT, CreationDate DATETIME, INDEX c CLUSTERED COLUMNSTORE);
INSERT #t_cci WITH (TABLOCK) -- A tab of locks
( UserId, VoteTypeId, CreationDate )
SELECT v.UserId, v.VoteTypeId, MAX(v.CreationDate)
FROM dbo.Votes AS v
WHERE v.UserId IS NOT NULL
GROUP BY v.UserId, v.VoteTypeId;
DROP TABLE IF EXISTS #t_cci;
GO
CREATE TABLE #t_cci (UserId INT, VoteTypeId INT, CreationDate DATETIME, INDEX c CLUSTERED COLUMNSTORE);
INSERT #t_cci -- A lack of tabs
( UserId, VoteTypeId, CreationDate )
SELECT v.UserId, v.VoteTypeId, MAX(v.CreationDate)
FROM dbo.Votes AS v
WHERE v.UserId IS NOT NULL
GROUP BY v.UserId, v.VoteTypeId;
The plans for those queries, in that order, look like this:
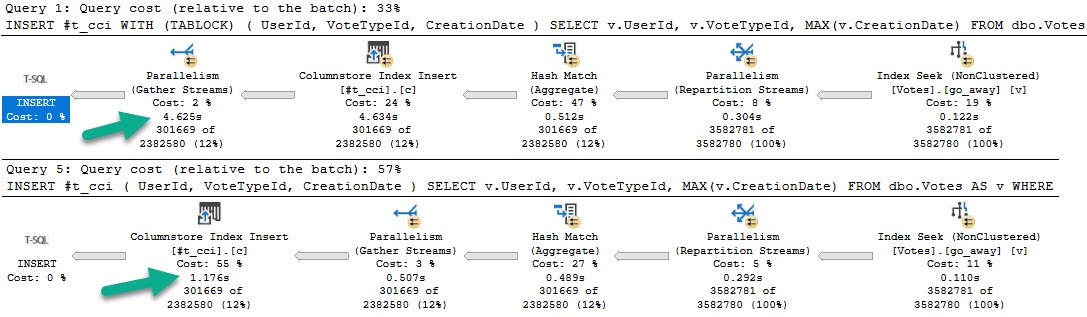
The fully parallel query takes 4.6 seconds, and the serial insert query takes 1.7 seconds.
Even more strange, the insert with tablock leaves four open rowgroups, and the non-tablock query has one compressed rowgroup.

Adding to that, using sp_spaceused on the temp tables, we can see some important differences.
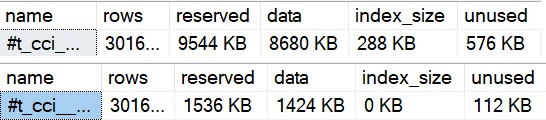
The uncompressed temp table is much larger, has more unused space, and has… index size?!
Yep, because open row groups, or delta stores, are stored as b-trees.
the columnstore index might store some data temporarily into a clustered index called a deltastore
I believe this happens with the parallel insert, because each thread inserts ~75k rows, which is fewer than the minimum 102,400 needed to qualify for skipping the delta store and being compressed. A simple way to test this is to run the tablock query at MAXDOP 2.

That ends up being a little faster than the serial insert, and also gets full compression.
Each thread is ~150k rows and gets compressed. Hooray.
Looking at a PerfView diff of the good and bad samples, this path is only present in the slow run:
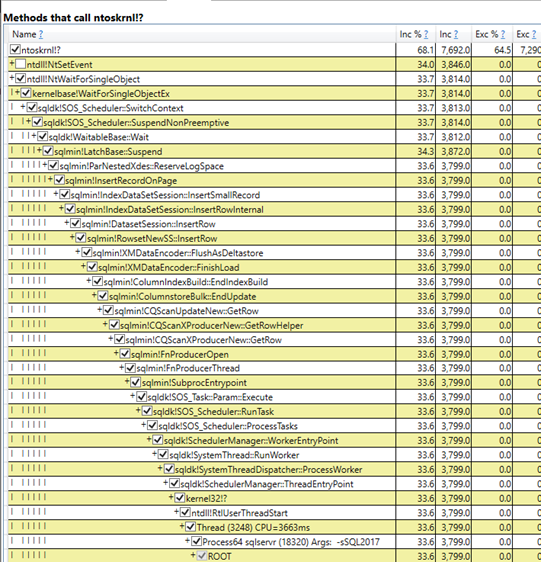
When inserting to the delta store, we need to acquire exclusive latches like just about any b-tree insert, and reserve log space to do so.
Morality Hilarity
To summarize the problem:
- The TABLOCK hint gets us a fully parallel insert plan
- There aren’t enough rows on each parallel thread to get row group compression
- We need to insert into a clustered index behind the scenes that makes up the delta store
- Which results in threads waiting on exclusive latches and reserving log space
Will you ever hit this? Maybe someday.
This will also happen with real tables (not just temp tables), so I suspect it’s a potentially common scenario for column store users.
You get all worked up getting these parallel inserts and then your compression sucks.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Great write-up, I believe it is well worth to link this blog from microsoft recommendation on inserting into the clustered columnstore table, very well presented!
Thanks, Dmytro! Glad you enjoyed it.
Good article, learned something new. If I know the amount of records I’m INSERTing is > 102,400 * the number of CPU cores my server is allocated, then can I rest assured this problem won’t ever be applicable to my use case of the TABLOCK HINT?
Not exactly, unless DOP for the query is equal to the number of cores in your server.