The End Is Nigh-Ish
Yes. SQL Server 2019. Scalar Function Inlining. Froid.
This post isn’t about any of that. It’s about scalar valued functions as we know them now.
Terrible, horrible, no-good, very-bad, presentation-filler.
But to make matters worse, we’re going to combine them with a problem no one is pretending to solve: bad parameter sniffing.
After all, that’s what can go wrong when you cache a plan, right?
Our Dummy
This is our function. It’s set up to do something that should happen on Stack sites: users should be penalized for leaving comments.
Okay, so this isn’t exactly how it would work. But stick with me, because it makes a better demo.
CREATE OR ALTER FUNCTION dbo.CommentsAreHorribleScalar(@Id INT) RETURNS BIGINT WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT AS BEGIN DECLARE @Tally BIGINT SELECT @Tally = (SELECT SUM(Score) FROM dbo.Posts AS p WHERE p.OwnerUserId = @Id) - (SELECT COUNT_BIG(*) FROM dbo.Comments AS c WHERE c.UserId = @Id) RETURN @Tally END GO
Really, we’re just getting a sum of all the scores in the Posts table for a user, then subtracting the count of comments they’ve left.
Because comments are horrible.
Anyway.
Individually
If we run these two queries, the plan will get reused.
SELECT dbo.CommentsAreHorribleScalar(22656); SELECT dbo.CommentsAreHorribleScalar(138);
We can free the cache, run them in the other order, and the same will happen in reverse.
Of course, each one gets a different plan.


Tangentially, these functions will end up dm_exec_function_stats, which was introduced in 2016, and can also be identified by name in the plan cache.
SELECT * FROM sys.dm_exec_function_stats AS defs; EXEC sp_BlitzCache @StoredProcName = 'CommentsAreHorribleScalar';
Sniffing
If we cache a plan for 22656 or 138, and then run a query like this:
SELECT TOP (100) u.DisplayName,
dbo.CommentsAreHorribleScalar(u.Id)
FROM dbo.Users AS u;
The query will reuse whatever the cached plan is.
Again, using BlitzCache to track the plan down:

In this case, the query is simple enough that the plan difference doesn’t change performance very much.
Let’s change our function a little bit to see a better example.
Appalled
Here it is:
CREATE OR ALTER FUNCTION dbo.CommentsAreHorribleScalar(@Id INT) RETURNS BIGINT WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT AS BEGIN DECLARE @Tally BIGINT SELECT @Tally = (SELECT SUM(Score) FROM dbo.Posts AS p WHERE p.OwnerUserId <= @Id) - (SELECT COUNT_BIG(*) FROM dbo.Comments AS c WHERE c.UserId <= @Id) RETURN @Tally END GO
The plans are way different now:
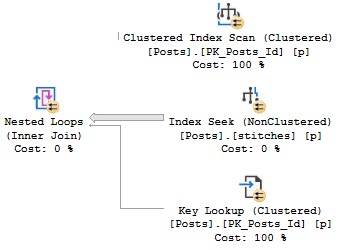
22656 scans the clustered index, and 138 seeks into the nonclustered index with a key lookup.
For the record, the bad plan is the clustered index scan, and the fast plan is the nonclustered index seek.
Running a smaller query (because the top hundred made me impatient), the difference is obvious.
SELECT TOP (5) u.DisplayName,
dbo.CommentsAreHorribleScalar(u.Id)
FROM dbo.Users AS u;
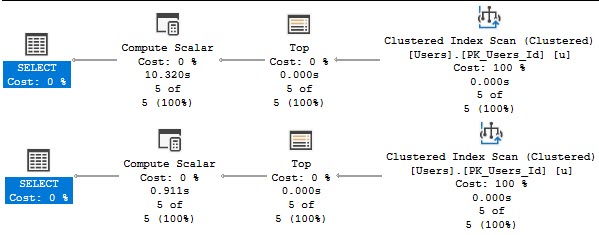
The version of the query that gets the bad function plan has a 10 second compute scalar, and the version of the query that gets the good function plan finishes in 900ms.
Functions Can Get Different Plans
Depending on how you call them, and how much data they might have to touch, this can be a big deal or no deal.
Because I know I’ll get some semi-related questions:
- The body of scalar functions have no restrictions on parallelism, only the calling statements are forced to run serially
- Functions run “once per row”, with the number of rows being dependent on where in the plan the compute scalar appears
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I pretty much only leave comments on SE (and blogs). And make edits too, I suppose. Better to leave the answers up to people who know what they’re doing. Or the ones promoting themselves. Ha!
Oddly, you need more reputation to leave an answer than to leave a comment.