Two Dollars
My Dear Friend™ Sean recently wrote a post talking about how people are doing index maintenance wrong. I’m going to go a step further and talk about how the method your index maintenance scripts use to evaluate fragmentation is wrong.
If you look at how the script you use to decide whether or not you’re going to rebuild indexes works, and this goes for maintenance plans, too (I ran PROFILER LONG LIVE PROFILER GO TEAM PROFILER to confirm the query), you’ll see they run a query against dm_db_index_physical_stats.
All of the queries use the column avg_fragmentation_in_percent to measure if your index needs to be rebuilt. The docs (linked above) for that column have this to say:

It’s measuring logical fragmentation. Logical fragmentation is when pages are out of order.
If you’re on decent disks, even on a SAN, or if you have a good chunk of memory, you’ll learn from Sean’s Great Post© that this is far from the worst fate to befall your indexes. If you keep up your stats maintenance, things will be okay for you.
Cache Rules
If you’re the kind of person who cares about various caches on your server, like the buffer pool or the plan cache, then you’d wanna measure something totally different. You’d wanna measure how much free space you have on each page, because having a bunch of empty space on each page means your data will take up more space in memory when you read it in there from disk.
You could do that with the column avg_page_space_used_in_percent.
BUT…

Your favorite index maintenance solution will do you a favor and only run dm_db_index_physical_stats in LIMITED mode by default. That’s because taking deeper measurements can be rough on a server with a lot of data on it, and heck, even limited can run for a long time.
But if I were going to make the decision to rebuild an index, this is the measurement I’d want to use. Because all that unused space can be wasteful.
The thing is, there’s not a great correlation between avg_fragmentation_in_percent being high, and avg_page_space_used_in_percent.
Local Database
When looking at fragmentation in my copy of the Stack Overflow 2013 database:
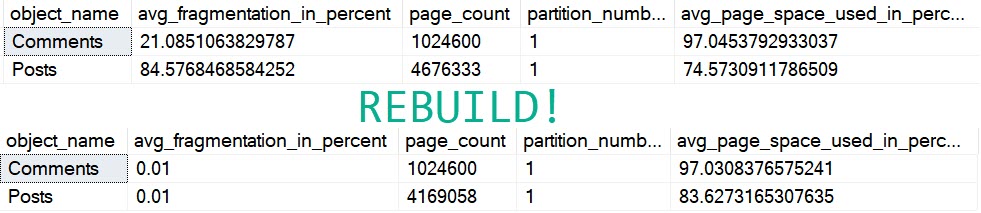
Both of those tables are fragmented enough to get attention from a maintenance solution, but rebuilding only really helps the Posts table, even though we rebuilt both.
On the comments table, avg_page_space_used_in_percent goes down a tiny bit, and Posts gets better by about 10%.
The page count for Comments stays the same, but it goes down by about 500k for Posts.
This part I’m cool with. I’d love to read 500k less pages, if I were scanning the entire table.
But I also really don’t wanna be scanning the entire table outside of reporting or data warehouse-ish queries.
If we’re talking OLTP, avoiding scanning large tables is usually worthwhile, and to do that we create nonclustered indexes that help our queries find data effectively, and write queries with clear predicates that promote the efficient use of indexes.
Right?
Right.
Think About Your Maintenance Settings
They’re probably at the default of 5% and 30% for reorg and rebuild thresholds. Not only are those absurdly low, but they’re not even measuring the right kind of fragmentation. Even at 84% “fragmentation”, we had 75% full pages.
That’s not perfect, but it’s hardly a disaster.
Heck, you’ve probably been memed into setting fill factor lower than that to avoid fragmentation.
Worse, you’re probably looking at every table >1000 pages, which is about 8 MB.
If you have trouble reading and keeping 8 MB tables in memory, maybe it’s time to go shopping.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Good morning Erik. So, here is where it seems that we have different SQL Server experts saying different things about the same topics. When I searched “SQLSkills Index Fragmentation” I found other articles that seem to indicate that fragmentation does still matter for performance, even when you have SSDs. There are also still recent references in their blog posts to one of the Accidental DBA posts on index fragmentation dating back to 2013. The assumption I’m making is that if they are still referencing that, then they stand by it.
My point isn’t to start an argument between the two sides as much as it is to say, that I see both sides of the argument. Because two groups of experts have wildly differing approaches, it sometimes makes it challenging to figure out what to do in my own environment.
Lee — that’s the thing, we mostly do agree. The kind of fragmentation that’s bad is from empty space on pages. That’s the kind I can quickly find references to using the same search as you, but feel free to let me know if I’m wrong there.
The problem is that empty space isn’t what your index maintenance scripts are measuring, nor is it closely tied to what they do measure. There are sound reasons to rebuild indexes, but logical fragmentation (pages out of order) isn’t one of them.
While low latency storage (local SSDs and fast network storage) reduce the effect of block location fragmentation (to the point where it is insignificant compared to other factors, and time fixing it is more wasteful than just letting it live), free space fragmentation is still an issue because it means page use is inefficient. If the same amount of data and indexes take more pages to store than they optimally would, then your working data set will need more memory and in some cases take measurably more CPU resource to work with (particularly if you are using compression for instance). Bad enough on local systems and potentially more directly costly on cloud architectures with pay-for-what-you-use pricing or similar. It also has an effect on backups and other important matters away from query processing.
Those are two different types of fragmentation, so saying one isn’t an issue these days but the other is, is not the contradictory set of opinions it can initially appear to be. It isn’t two sides of an argument, it is two related arguments with very similar terminology (specifically the word fragmentation).
It would help if there were consistently used differentiating terms for them. Some refer to internal and external fragmentation, but those terms have different meanings depending on which level of your storage architecture you are looking at so can add further confusion. Physical and logical fragmentation can have different meanings depending on context and interpretation too. I’m not entirely happy with the “page location fragmentation” and “free space fragmentation” terms that I tend to use, though they are at least usefully more specific IMO, so I for one am open to suggestions.
Hi Erik,
I see your point, I’m only wondering if there is any open source solution (like MinionWare or Ola.Halengren) that you have seen out there and you could recommend approaching index maintenance from that standpoint.
If not, I’m guessing this is probably a good time to visit Ola on Git Hub or MinionWare website and put down a feature request… what do you guys think?
https://github.com/olahallengren/sql-server-maintenance-solution/issues/new/choose
https://minionware.freshdesk.com/support/discussions/forums/43000119867
Not that I’m lazy to build my own stuff (well.. maybe a bit…) but I can see people would likely continue to use stuff such as Ola’s or MinionWare solutions because they are a convenient “bundle” for backup/integrity/index maintenance (all in one package) so even when there may be better ways of doing Index Maintenance, the best way to ensure people actually implement that is by incorporating those recommendations there as opposed to part in different ways…
Cheers!
Martin — no, I wouldn’t want either of them to try to measure physical fragmentation. It’s a much more invasive procedure. I think I mention that in the post.
I’d love to hear any good argument for defragmenting indexes stored on SSD.
Right off the top of my head, there are at least 6…
1. Wasted RAM.
2. Wasted SSD space.
3. Slower Read-Aheads and related query problems (even with SSDs)
4. Totally unnecessary page splits.
5. Totally unnecessary log file activity and unnecessarily large log file backups.
6. Slower restores.
So, a potential gatcha would be a be a low fill factor. Also, I have a hard time believing hard drive performance just no longer matters for fragmentation (we have been deigned SSDs).
Also, isn’t this similar to table compression in that you are just getting more rows per page? I know there is some CPU overhead compression, but shouldn’t compression be considered as well if free space on a page is an even bigger issue that fragmentation?
“but shouldn’t compression be considered as well if free space on a page is an even bigger issue that fragmentation”
Absolutely yes, it should be considered.
But the “some CPU overhead” might be a fair chunk more than it sounds like you are expecting. The compressed pages are held in the buffer pool in memory in their compressed state, not just when on disk, so the page must be decompressed every time a row on it is accessed not just every time it is read from permanent storage (for page compression, for row compression the extra work it less of course). Also, some data simply does not compress well, so you would be potentially wasting all that CPU time if you applied compression without any verification that it is useful.
Another thing to consider once you are using SQL2019 (or are using Azure SQL and for now are happy to use “preview” features) is replacing N[VAR]CHAR(x) columns with [VAR]CHAR(x) columns using UTF8. For English text this will usually result in nearly a 50% reduction in space used for those columns without quite the same overheads of compression. This is effectively the same benefit as the “Unicode compression” that comes for free with row- and page- compression, without the other extra work.
+1000
Hi Erik,
You say, “They’re probably at the default of 5% and 30% for reorg and rebuild thresholds. Not only are those absurdly low”. I have proof that even 5% is waiting way too long. Most people will never understand that, though, because not only are they not looking at the right things to trigger index maintenance, but they’re also doing index maintenance absolutely incorrectly.
What they don’t understand is that doing the index maintenance incorrectly, they end up perpetuating page splits which perpetuates the need for index maintenance which perpetuates page splits, ad infinitum.
A great example of this is what I have in my “Black Arts Index Maintenance #1” presentation. How long do you believe that (for example), you can have a 123 byte wide Clustered Index keyed on a random GUID can go for without any bad page splits and, so, absolutely zero fragmentation when inserting 1,000 RBAR rows per hour for 10 hours per day when there are about 3 million rows already in the table? In fact, do you believe that there will actually be no good page splits either?
And what if I told you the defrag routine is set to defrag when we hit only 1% logical fragmentation? Now how long would you say we could go with absolutely 0 page splits of any kind on that same 123 byte wide, random GUID keyed, Clustered Index?
As far as the terms for fragmentation, I know only 3…
1. Logical fragmentation (based on percent of fragmentation), which is a misnomer in itself because it’s also physical fragmentation.
2. Page Density, which is mostly physical fragmentation but results in logical fragmentation, as well.
3. Disk (or file) fragmentation, which most people aren’t even aware of these days.
p.s. The answer to my questions above is that, under the conditions given and using an 80% Fill Factor, you can go for 4.5 weeks with zero page splits of any kind (good or bad) and should do proper index maintenance at 1% logical fragmentation to go for nearly 5 more months (it gets longer the larger the number of rows are over time) . Even at a 90% Fill Factor, you can still go 9 days with zero fragmentation and at 70%, you can go more than 2 months. And, remember… the key on the Clustered Index is a random GUID.
The problem is that the supposed “Best Practices” (even the guy that wrote them doesn’t call them “Best Practices) methods for Index Maintenance is the worst practice possible.
I don’t want to give it all away here. I want people to come to my SQLSaturday presentations and I’m writing a “Stairway” on SQL Server Central about the current train wreck that people call “Index Maintenance”.
Oh yeah… the people that are saying that you don’t need to do “Index Maintenance” to maintain performance are mostly correct. But they’re also wrong… you absolutely DO need to do Index Maintenance… just NOT like almost everyone in the whole world is doing/recommending.
Hi Jeff — yep, I’ve seen those decks — great stuff!
Hi Erik,
maybe this article from Mike Byrd can be interesting:
https://www.sqlservercentral.com/articles/a-self-tuning-fill-factor-technique-for-sql-server-part-1
Hm, yeah, that’s still measuring average fragmentation in percent rather than page fullness — what’d you want me to look at?
Thanks!
Publishing such an important piece without an accompanying T-SQL script is a travesty, Erik!
How else should people put your recommendations into action??
God forbid, they may have to write their own scripts! Oh my!
Uh… So, anyways I wrote my own script.
I uploaded it to my GitHub Gists so that it’d be easy to maintain and improve with time.
I’d love your feedback!
Check it out here:
https://gist.github.com/EitanBlumin/4fb686ffa07c6f4fd96595f01ec2f1dd
Haha, cool! Yeah, see, if I tried to write something like that it wouldn’t be nearly as good. I’m glad you did it.
Thanks!
version 10.50.6529 (I know, I know) reports
Correlated parameters or sub-queries are not supported by the inline function “sys.dm_db_index_physical_stats”.
Sounds like an unsupported configuration to me 😀
In every sense of the word. ?