This Comes Up A Lot
When I’m working with clients, people who don’t spend a lot of time working with indexes have a lot of questions about indexes.
The general rule about leading column selectivity is an easy enough guideline to follow, but what happens if you’re not looking for equality predicates?
What if you’re looking for ranges, and those ranges might sometimes be selective, and other times not?
LET’S FIND OUT!
Chicken and Broccoli
Let’s take these queries against the Posts table. The number next to each indicates the number of rows that match the predicate.
SELECT COUNT_BIG(*) AS records /*6050820*/ FROM dbo.Posts AS p WHERE p.ParentId < 1 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records /*3*/ FROM dbo.Posts AS p WHERE p.Score > 19000 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records /*23*/ FROM dbo.Posts AS p WHERE p.ParentId > 21100000 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records /*6204153*/ FROM dbo.Posts AS p WHERE p.Score < 1 AND 1 = (SELECT 1);
In other words, sometimes they’re selective, and sometimes they’re not.
If we run these without any indexes, SQL Server will ask for single column indexes on ParentId and Score.
But our queries don’t look like that. They look like this (sometimes):
SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WHERE p.ParentId < 1 AND p.Score > 19000 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WHERE p.ParentId > 21100000 AND p.Score < 1 AND 1 = (SELECT 1);
When we run that, SQL Server asks for… the… same index.
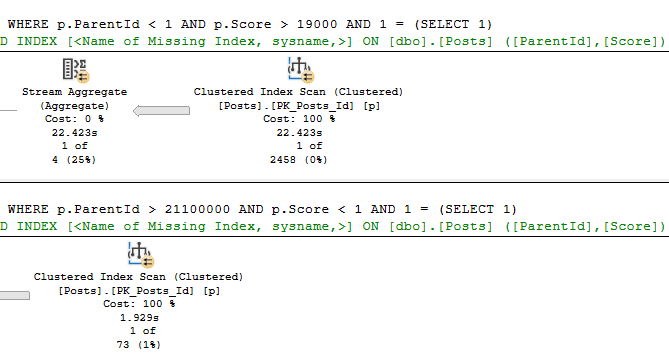
Missing index request column order is pretty basic.
Instead, we’re gonna add these:
CREATE INDEX ix_spaces ON dbo.Posts(ParentId, Score); CREATE INDEX ix_tabs ON dbo.Posts(Score, ParentId);
Steak and Eggs
When we run those two queries again, each will use a different index.

Those finish in, apparently, NO TIME WHATSOEVER.
And they do pretty minimal reads.
Table 'Posts'. Scan count 1, logical reads 4 Table 'Posts'. Scan count 1, logical reads 4
If we force those queries to use the opposite index, we can see why SQL Server made the right choice:
SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WITH (INDEX = ix_spaces) WHERE p.ParentId < 1 AND p.Score > 19000 AND 1 = (SELECT 1); SELECT COUNT_BIG(*) AS records FROM dbo.Posts AS p WITH (INDEX = ix_tabs) WHERE p.ParentId > 21100000 AND p.Score < 1 AND 1 = (SELECT 1);
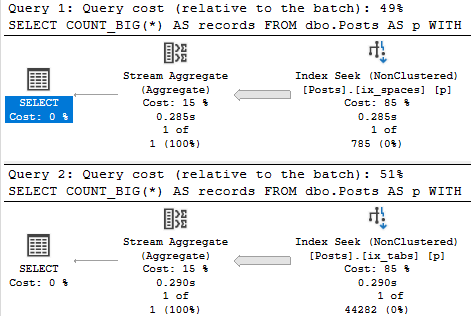
Time was discovered. As were a bunch more reads.
Table 'Posts'. Scan count 1, logical reads 13519 Table 'Posts'. Scan count 1, logical reads 13876
Sweaty Mess
Having two indexes like that may not always be the best idea.
To make matters worse, you probably have things going on that make answers less obvious, like actually selecting columns instead of just getting a count.
This is where it pays to look at your indexes over time to see how they’re used, or knowing which query is most important.
There isn’t that much of a difference in time or resources here, after all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I always look in the DMV sys.dm_db_index_usage_stats to see what actually gets used. As we also run re-indexing and updating of stats jobs I can only get an approximate picture as I am not sure how these operations will affect the access numbers. But I do know that if an index gets used it will populate the DMV.
Why the `AND 1 = (SELECT 1)`? It seems superfluous to requirements.
“Seems”, yes. In practice, no.