Don’t Mask Spools
Certain spools in SQL Server can be counterproductive, though well intentioned.
In this case, I don’t mean that “if the spool weren’t there, the query would be faster”.
I mean that… Well, let’s just go look.
Bad Enough Plan Found
Let’s take this query.
SELECT TOP (50)
u.DisplayName,
u.Reputation,
ca.*
FROM dbo.Users AS u
CROSS APPLY (
SELECT TOP (10)
p.Id,
p.Score,
p.Title
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
ORDER BY p.Score DESC
) AS ca
ORDER BY u.Reputation DESC;
Top N per group is a common enough need.
If it’s not, don’t tell Itzik. He’ll be heartbroken.
The query plan looks like this:
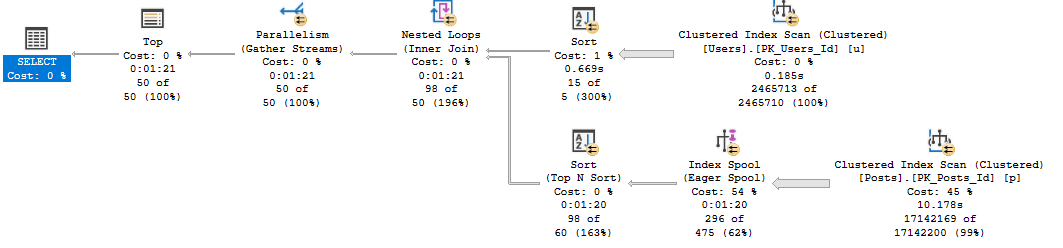
Thanks to the new operator times in SSMS 18, we can see exactly where the chokepoint in this query is.
Building and reading from the eager index spool takes 70 wall clock seconds. Remember that in row mode plans, operator times aggregate across branches, so the 10 seconds on the clustered index scan is included in the index spool time.
One thing I want to point out is that even though the plan says it’s parallel, the spool is built single threaded.
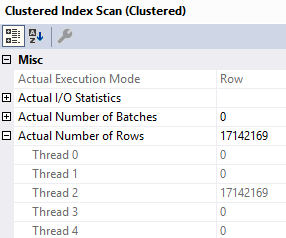
Reading data from the clustered index on the Posts table and putting it into the index is all run on Thread 2.
If we look at the wait stats generated by this query, a full 242 seconds are spent on EXECSYNC.
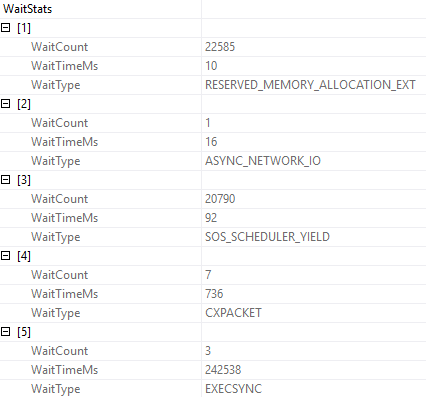
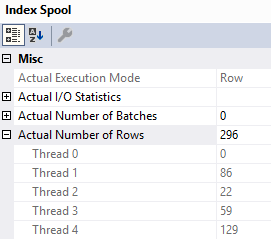
The math mostly works out, because four threads are waiting on the spool to be built.
Even though the scan of the clustered index is serial, reading from the spool occurs in parallel.
Connected
Eager index spools are built per-query, and discarded afterwards. When built for large tables, they can represent quite a bit of work.
In this example query, a 17 million row index is built, and that’ll happen every single time the query executes.
While I’m all on board with the intent behind the index spool, the execution is pretty brutal. Much of query tuning is situational, but I’ll always pay attention to an index spool (especially because you won’t get a missing index request for them anywhere). You’ll wanna look at the spool definition, and potentially create a permanent index to address the issue.
As for EXECSYNC waits, they can be generated by other things, too. If you’re seeing a lot of them, I’m willing to bet you’ll also find parallel queries with spools in them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.