Batch Cussidy
In the last post, we looked at how SQL Server 2019’s Batch Mode for Row Store could have helped our query.
In short, it didn’t. Not because it’s bad, just because the original guess was still bad.
Without a hint, we still got a poorly performing Merge Join plan. With a hint, we got a less-badly-skewed parallel plan.
Ideally, I’d like a good plan without a hint.
In this post, I’ll focus on more traditional things we could do to improve our query.
I’ll approach this like I would if you gave me any ol’ query to tune.
Here’s what we’re starting with:
SELECT p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
ORDER BY p.Id;
First Pass
I don’t know about you, but I typically like to index my join columns.
Maybe not always, but when the optimizer is choosing to SORT 52 MILLION ROWS each and every time, I consider that a cry for help.
Indexes sort data.
Let’s try that first.
CREATE INDEX ix_fluffy ON dbo.Votes(PostId);
This is… Okay.
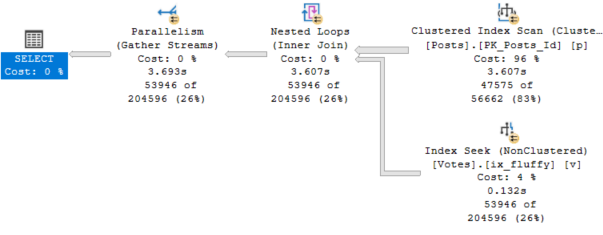
I’m not saying this plan is great. It’s certainly faster than the Merge Join plan, and the optimizer chose it without us having to hint anything.
It takes 3.6 seconds total. I think we can do better.
Second Pass
I wonder if a temp table might help us.
SELECT *
INTO #p
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225';
This is… Okay. Again.
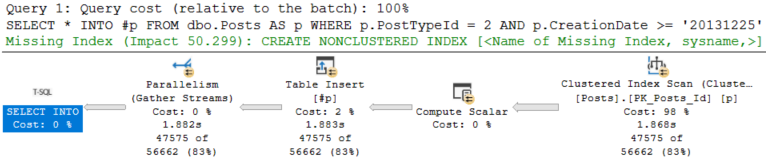
The Insert takes 1.8 seconds:
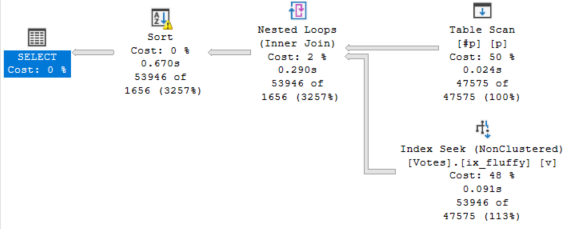
The final select takes 670ms:
Usually this is the point where I’ll stop and report in:
“I’ve spent X amount of time working on this, and I’ve gotten the query from 27 seconds down to about 2.5 seconds. I can do a little more and maybe shave more time off, but I’ll probably need to add another index. It’s up to you though, and how important this query is to end users.”
We could totally stop here, but sometimes people wanna go one step further. That’s cool with me.
Third Pass
The insert query is asking for an index, but it’s a dumb dumb booty head index.
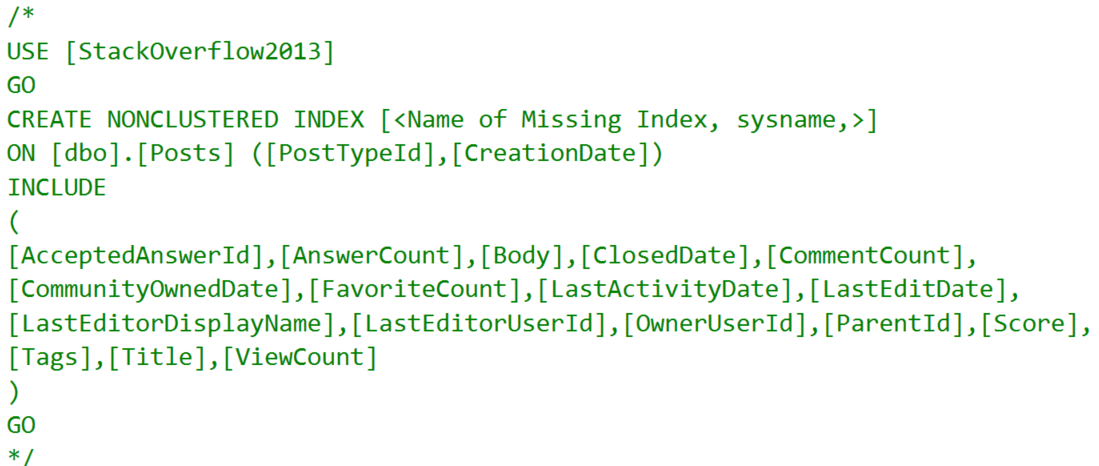
Yep. Include every column in the table. Sounds legit.
Let’s hedge our bets a little.
CREATE INDEX ix_froggy ON dbo.Posts(PostTypeId, CreationDate);
I bet we’ll use a narrow index on just the key columns here, and do a key lookup for the rest.
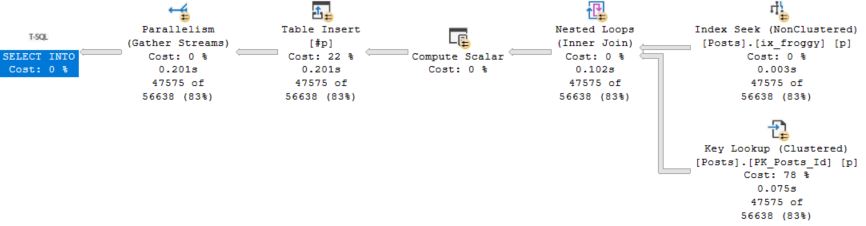
This time I was right, and our Insert is down to 200ms.
This doesn’t change the speed of our final select — it’s still around 630-670ms when I run it.
Buuuuuuut, this does get us down to ~900ms total.
Final Destination
Would end users notice 900ms over 2.5 seconds? Maybe if they’re just running it in SSMS.
In my experience, by the time data ends up in the application, gets rendered, and then displayed to end users, your query tuning work can feel a bit sabotaged.
They’ll notice 27 seconds vs 2.5 seconds, but not usually 2.5 seconds vs 1 second.
It might make you feel better as a query tuner, but I’m not sure another index is totally worth that gain (unless it’s really helping other queries, too).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Are we allowed to think outside the box with this query?
1. Does the application really need to SELECT * to pull all of the columns from the Posts table?
2. The join between the 2 tables is multiplicative, but only columns from the Posts table are returned. Does the application really want/need duplicate Post records, or would using an EXISTS check against the Votes table work better than the join?