Spoolwork
I wanted to show you two situations with two different kinds of spools, and how they differ with the amount of work they do.
I’ll also show you how you can tell the difference between the two.
Two For The Price Of Two
I’ve got a couple queries. One generates a single Eager Index Spool, and the other generates two.
SELECT TOP (1)
u.DisplayName,
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id) AS [Total Badges]
FROM dbo.Users AS u
ORDER BY [Total Badges] DESC;
GO
SELECT TOP (1)
u.DisplayName,
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date ) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
AND u.LastAccessDate >= b.Date) AS [Whatever],
(SELECT COUNT_BIG(*)
FROM dbo.Badges AS b
WHERE b.UserId = u.Id) AS [Total Badges]
FROM dbo.Users AS u
ORDER BY [Total Badges] DESC;
GO
The important part of the plans are here:

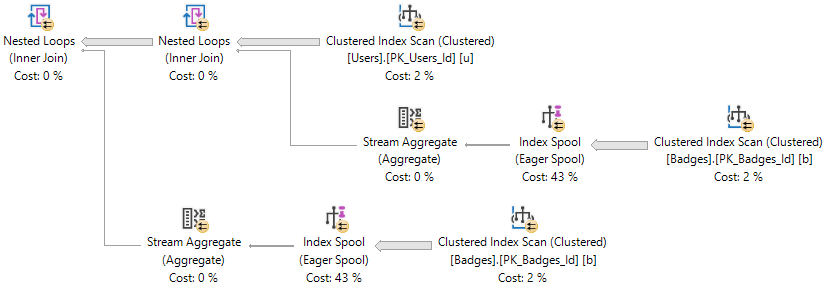
The important thing to note here is that both index spools have the same definition.
The two COUNT(*) subqueries have identical logic and definitions.
Fire Sale
The other type of plan is a delete, but with a different number of indexes.
/*Add these first*/ CREATE INDEX ix_whatever1 ON dbo.Posts(OwnerUserId); CREATE INDEX ix_whatever2 ON dbo.Posts(OwnerUserId); /*Add these next*/ CREATE INDEX ix_whatever3 ON dbo.Posts(OwnerUserId); CREATE INDEX ix_whatever4 ON dbo.Posts(OwnerUserId); BEGIN TRAN DELETE p FROM dbo.Posts AS p WHERE p.OwnerUserId = 22656 ROLLBACK
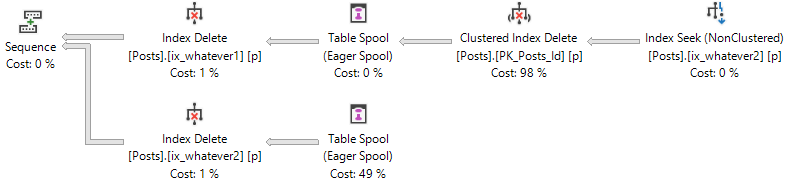

Differences?
Using Extended Events to track batch completion, we can look at how many writes each of these queries will do.
For more on that, check out the Stack Exchange Q&A.
The outcome is pretty interesting!

- The select query with two spools does twice as many reads (and generally twice as much work) as the query with one spool
- The delete query with four spools does identical writes as the one with two spools, but more work overall (twice as many indexes need maintenance)
Looking at the details of each select query, we can surmise that the two eager index spools were populated and read from separately.
In other words, we created two indexes while this query ran.
For the delete queries, we can surmise that a single spool was populated, and read from either two or four times (depending on the number of indexes that need maintenance).
Another way to look at it, is that in the select query plans, each spool has a child operator (the clustered index scan of Badges). In the delete plans, three of the spool operators have no child operator. Only one does, which signals that it was populated and reused (for Halloween protection).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One thought on “Do Query Plans With Multiple Spool Operators Share Data In SQL Server?”
Comments are closed.